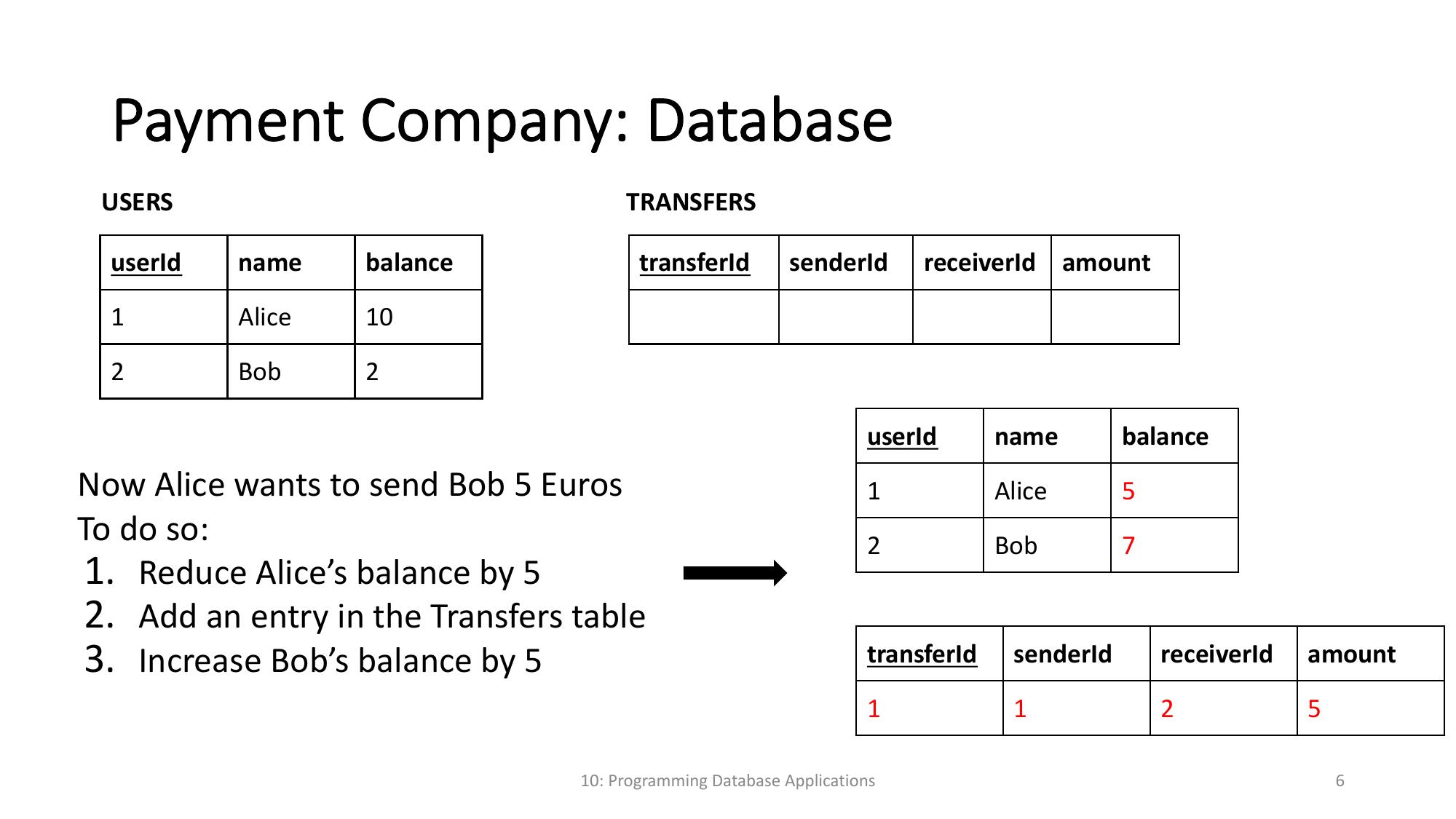
Wir implementieren die Logik mithilfe von stored procedures
Diese werden in der Datenbank hinterlegt und sorgen dafür, dass immer alle drei sachen ausgeführt werden, auch wenn wir nur einen Aufruf haben
Wir limitieren den Beispiel zum DBMs mit dem integrierten DBMs access management
Das können wir machen, indem wir jedem user seinen eigenen User erstellen, womit er nur auf SEINE daten zugreifen kann, und auf daten die mit ihm geteilt sind
Wir entwickeln einen Client der die Datenbank wegabstrahiert und den Useren erlaubt "einfach" die App zu nutzen, ohne das sie fähigkeiten oder wissen zu den DBMS oder auch SQL haben müssen
Wir entwickeln einen DB driver (oder naja, nutzen einen bestehenden) der dann das CLI ersetzt.
Dann können wir auch "einfach" eine App oder ein Webinterface oder so schreiben, was dann alles implementiert etc.
Das hört sich doch erstmal alles super toll an, oder?
Wir haben wenige bewegliche teile
wir brauchen nur das DBMs und seine clienten aufrecht zu erhalten
der Client ist relativ leicht
Wir haben Sicherheit indem wir die Privilegien gut rausseperieren können
Damit ein Angreifer etwas "sinnvolles" erreichen kann, muss er das DBMS selber angreifen
Das ist sichergemacht dadurch, dass wir unseren Nutzern generell nicht vertrauen
Und wir sind gegen datenverlust gesichert
Denn wenn eitrwa fehlt, werden unsere daten wieder schön zurückgerollt
weil das eben so durch das DBMs überwacht wird
Ganz so rosig ist das dann aber doch nicht
Für entwickler ist das ein bissl sehr nervig
Stored Procedured sind halt schon nen bissl massiv nervig
Testen wird sehr schwer, weil die stored Procedures halt nicht teil des programms selber sind, sondern irgendwie anders im DBMS liegen und so schlecht getestet werden können
Ebenfalls wird das dadurch sehr schwer das zu debuggen
Denn die stored procedures nerven ein wenig und sind halt irgendwie nicht besonders "toll" und loggen auch nicht wirklich
Leider sind die errors die wir hierfür bekommen dementsprechend besonders kryptisch und machen generell keinen spaß zu debuggen
Ausserdem muss die Datenbank eben an die clients exposed werden, was inhärent ein Sicherheitsrisiko ist, was dazu führt, dass wir uns direkt wieder ein weniger unsicher machen
Zudem entsteht dadurch eben eine vermeindlich große angriffsfläche, die halt für uns dann wieder nen bissl schlecht sind
wenn eine Datenbank direkt ins Internet exposed ist, macht uns das direkt angreifbar und ist generell ne ziemliche bad practise
Wir implementieren unsere Business Logic innerhalb des clients in der Sprache des clients
Hier können wir dann unsere lieblingssprache nehmen und dann dementsprechend ggf. auch schöner einbinden
Die clienten können ausserdem schneller und genauer auf daten zugreifen, weil sie durch die direkte implementation einfacher zum bearbeiten sind
jetzt können wir deutlich sicherere permissionsverteilung machen
leider müssen die clients immernoch "direkten" zugriff haben, dennoch sollte das dann einfacher möglich sein
wir müssen allerdings weiterhin "einfach vertrauen" denn irgendwie kommen wir da nicht herum
Wenn leute Zugriff auf den client haben, können sie ausserdem das passwort o.ä. "einfach" direkt aus dem client auslesen, und dann halt dementsprechend auch einfach blöde dinge tun
wenn unsere Datenbank nicht richtig gesichert ist, könnten sie zudem auch einfach die daten von anderen leuten anschauen oder traffic snoopen
Leider funktioniert das alles nur, wenn der Client wirklich vertrauenswürdig ist
die GUI ist weiterhin einfach eine GUI, genau so wie vorher
Ist das die lösung für uns alle?
Es ist immernoch sehr simpel
wir brauchen immernoch nur das RDBMS und müssen nur clienten accounts machen
Jetzt ist die Development Experience deutlich schöner
die logik ist in "richtigen" programmiersprachen deutlich durchsichtiger und wir können dementsprechend echt schön alles filtern etc.
Das debuggen ist auch einfacher, denn alles ist ja wie gesagt einfach direkt integriert
Leider immernoch nicht das Rezept für den Weltfrieden
Wir müssen weiterhin unseren clients vertrauen, was wir irgendwie immernoch nicht machen wollen
Da die user immernoch von ihrem gerät aus zugreifen, könnten die einfach irgendwas machen, usw.
Daher müssen wir auch jedes mal, wenn irgendetwas an der DB geändert wird, den Client updaten, und alle bisherigen clients gehen einfach kaputt, was halt auch nen bissl blöd ist
Ausserdem muss jetzt alles in jedem client gespeichert werden, was irgendwie nicht so geil ist
Vor allem wenn wir ein cross-plattform system nutzen, ist das echt irgendwie nicht besonders toll, und wir müssen dementsprechend das jedes mal irgendwie neu machen
Wie gesagt muss die DB immernoch ans offene Internet exposed werden, was halt am ende dann doof ist
Wir implementieren weiterhin die Business Logic in einer "tollen Programmiersprache"
Hier nutzen wir weiterhin die vorteile davon, alles integriert zu machen
Wir autorisieren jetzt auf einem application server
Der Server ist von uns trusted, und kann so "mehr" machen
Wir steuern den über HTTP an und müssen so nicht mehr die DB exposen
Wir können deutlich feiner seperieren und mit deutlich mehr genauigkeit autorisieren
Der Client ist jetzt "simpler" und interfaced nur mit dem Server
So müssen wir die Datenbank nicht mehr ans internet exposen, und alles wird für uns unendlich einfacher (yay)
Bei updates an der datenstruktur etc müssen wir nicht immer den Client updaten, denn jetzt kann der Server etwas als "übersetzer" fungieren
Der client enthält nichts mehr von der "richtigen Datenbank" und kann dementsprechend auch nicht mehr dadrauf zugreifen oder durch irgendwas dummes die Datenbank compromisen
Gutes beispiel sind hier websiten
Jetzt ist das wohl unser Erfolgsrezept?
Die development experience ist wie gesagt weiterhin toll
Das debuggen ist noch einfacher, denn wir wissen direkt in welchem teil der "Kette" das alles passiert
Wir müssen das DBMS nicht exposen
Der Server ist warscheinlich auch generell einfacher zu sichern, als eben das DBMS
Änderungen in der Datenbank macht uns nicht direkt den Client kaputt, denn der Server kann hier übersetzen
Dementsprechend müssen wir nur eine sache updaten, und nicht wieder jeden client der überall auf der welt sein kann
Wir können permission sehr schön ausseinanderhalten
Naja nichts im leben ist "einfach" nur toll#
Wir haben einen höheren entwicklungsaufwand, denn wir müssen jetzt auch noch einen Server entwickeln und die Clients müssen irgendwie auch mit dem Server kommunizieren
Wir haben mehrere sachen die kaputt gehen können, denn jetzt haben wir ja auch noch den client
Wenn der Server aus irgendwelchen gründen übernommen werden kann, ist unsere datenbank trotzdem hiii
Das ist halt wieder doof, weil wir denken, dass wir unserem server vertrauen können
Allerdings ist hier auch wieder die best practise wichtig, einfach generell so wenig daten zu verteilen wie möglich
Die Architektur die wir uns aussuchen hat am ende dann doch noch wirklich große auswirkungen auf die Sicherheit unserer App und ist dementsprechend auch sehr wichtig
Leider kann man das auch irgendwie nicht später ändern und dementsprechend ist hier sehr gute überlegung vorher wichtig
Die Wahl der Architektur ist aber auch oft einfach mehr abhängig von den umständen in denen wir uns gerade befinden, als das wir wirklich einfach tolle sachen machen können
Manchmal kann man aber auch einfach mischen, was uns dann "the best of both worlds" liefern kann
Es kann aber auch einfach maximal schlimm sein (oh no)
Die meissten DBMS unterstützen alle oben erwähnten modelle, weil sich für die halt am ende auch nicht so viel ändert
wenn wir programme schreiben haben die programme auch gleichzeitig die möglichkeit unsicher zu sein
das ist (meisstens) nichts was wir uns aussuchen, aber dennoch kann das einfach passieren
So können z.b. SQL Injecitons passieren, wenn man unvorsichtig ist
Die dinger kann man umgehen, wenn man seinen Input Sanitized
Das machen wir, indem wir nach schemata suchen, und hier ist nicht einfach nur "String" eine sinnvolle abfrage
Generell ist es eine dumme Idee, den nutzern überhaupt zu vertrauen
Wir sollten also vermeiden, direkt nutzersachen in die Datenbank zu kloppen
Wie machen wir das? mit prepared statements.
Die prepared Statements können dann für uns einfach die sanitazation machen lassen
Denn die können das bestimmt besser als du und ich (zusammen)
Allerdings schreiben wir hier immernoch unsere Queries selber
Das kann zu fehlern führen, die oft auch schwer zu finden sind
Zudem müssen wir die daten aus dem RDMS "von hand" in die SQL queries mappen, und andersrum
Ausserdem passen oft die datentypen nicht, schaut euch teilweise auch einfach mal JS an (da passt eh nie irgendwas, also naja...)
Das können wir übergehen, indem wir einen Object Relational Mapper oder auch ORM nutzen.
Das ding, kümmert sich darum, das sachen die wir "einfach" in unserer lieblingsprogrammiersprache anwenden können auch in der SQL datenbank dann funktionieren.
Dadurch können oft fehler und sicherheitsücken unterbunden werden
dann du interagiertst nicht mehr direkt mit der datenbank, denn eben das (was auch der "gefährliche" teil ist) macht jetzt der ORM
Ausserdem ist das dann von der developer experience deutlich schöner, da alles einfach innerhalb deiner programmiersprache passiert
Ein (scheinbar) bekanntes ORM-System ist "Hybernate"
Das ding ist nen framework für Java was von einer Firma namens "JBoss" (schon kranker name) entwickelt wurde und heutezutage (wie so vieles) von den menschen mit dem Roten Hut (RedHat) maintained wird
Hibernate verfolgt hauptsächlich den weg des "Data Mappers", denn es generiert einfach allen SQL kran selber, und macht dementsprechend auch alle sachen die bei umzügen anfallen selber
Es greift auf Annotations zurück die mit den Tablestrukturen populiert werden, was dann dme ding alle "Wichtigen infos gibt"