Hashing II
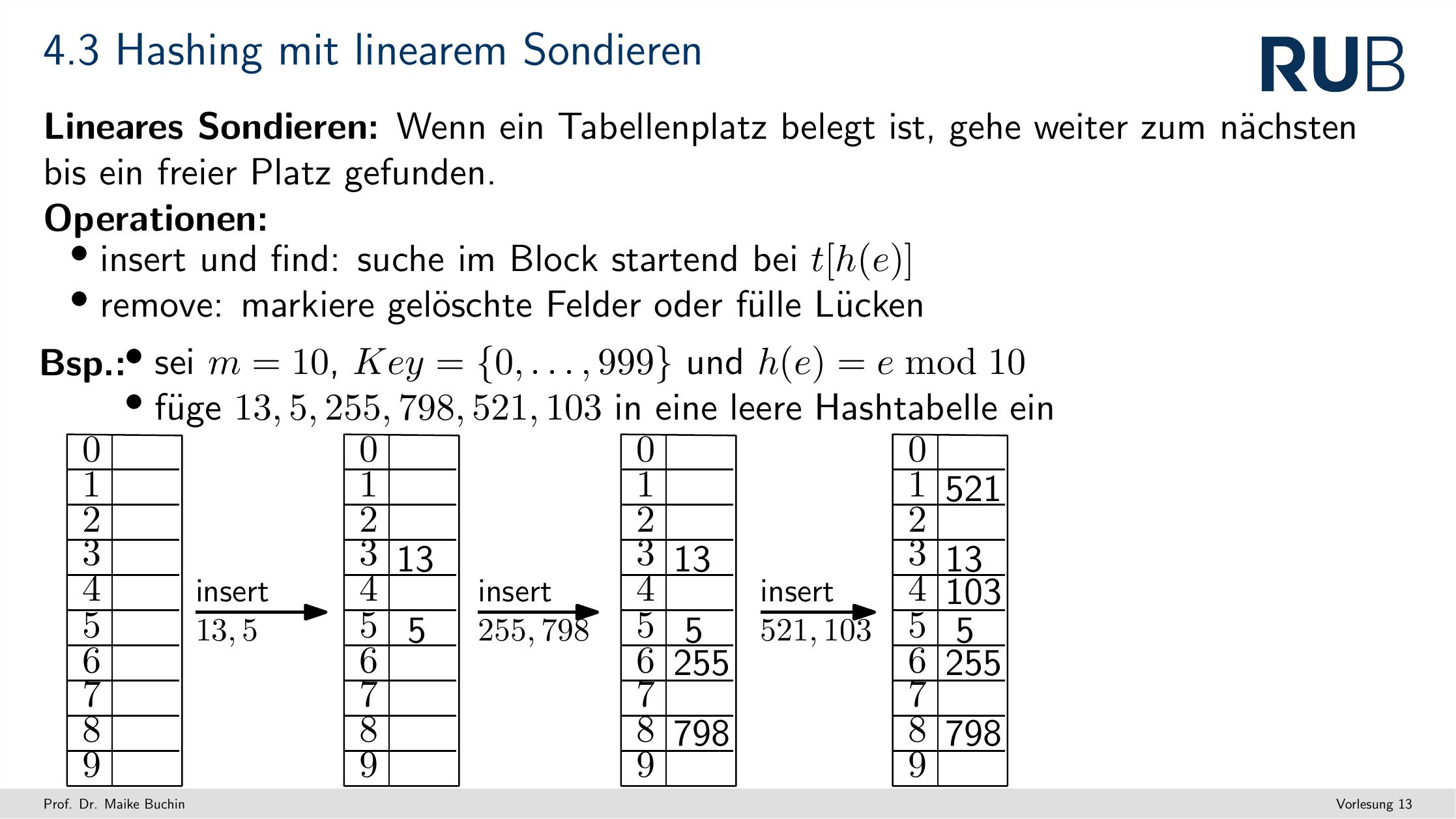
Hashing mit liearem Sondieren
- Wir nutzen einfach die hashfunktion als "sortierverfahren"
- Wenn eine Zelle schon voll ist, dann schauen wir, ob wir in die zelle danach rutschen können
- So entstehen dann blöcke, und dann können wir da "einfacher" finden
- Wenn wir dann etwas aus der Map löschen wollen, und dann am ende irgendwas fehlt, können wir diese "blöcke" wieder zusammenschieben und damit dann lücken füllen
Analyse
-
Vergleich
- Naja wenn wir das dann vergleichen, haben wir ein paar "lustige" erkentnisse
- Hashing mit verkettung braucht einen Extra zeiger, aber wir wissen, dass jeder index auch wirklich auf seinen Wert zeigt
- Beim linearen Sondieren, ist das leider nicht so, allerdings brauchen wir keine zusätzlichen speichersegmente und nutzen den gegebenen Speicherplatz effizienter.
Dazu kommt dann aber leider nochm, dass wir durch die "enge" packung eine höhere Suchdauer haben - Wenn wir aber das "beste" in einer bestimmten Situation brauchen, müssen wir uns eine "Perfekte Hashfunktion" basteln
Perfektes Hashing
- Wenn wir unsere bisherigen verfahren anschauen, garantieren die alle "nur" erwartete Laufzeiten in . Leider reicht das aber nicht immer aus
- Hier kommen perfekte hashfunktionen ins spiel.
- Eine Hashfunktion nennen wir "perfekt", wenn sie so effizient wie möglich ohne kollissionen auf unserem gegebenen Dataset funktioniert.
Wenn eine Hashfunktion keine Kollissionen hat, nennen wir das auch injektiv - Formell sieht das dann so aus:

Verfahren
- Wir wollen Beispielsweise eine Hashfunktion mit quadratischem Platz haben