Hashtabellen implementieren halt das Dictionary (jedenfalls nennt glasi das so)
Mir wird zugeflüstert, dass man das auf Deutsch auch "assoziatives Array" nennt, noch nie gehört ehrlich gesagt
Die dinger haben ein paar (mehr oder weniger) sinnvolle operationen
aufbauen
einfügen
löschen
suchen
Zum vergleich:
Queues erlauben nur insert und deleteMin (also älteste element löschen)
Sortierte Folgen erlauben locate, insert und delete
Wir brauchen also O(n) Platzbedarf und verarbeiten alles idealerweise in O(1) Zeit.
Wir betrachten die Menge S von Eintragen mit Schlüsseln key(e)∈Key
Am ende nutzen wir eine Hashfunktion
Wenn wir was reinwerfen kriegen wir den hash (also ne Zahl in diesem fall) raus
Und die hashtabelle (dat einfach nen Array)
Leider können in diesem Approach immernoch Elemente / indizes Kollidieren, was es zu vermeiden gilt
Daher müssen wir uns dafür eine Alternative Ausdenken
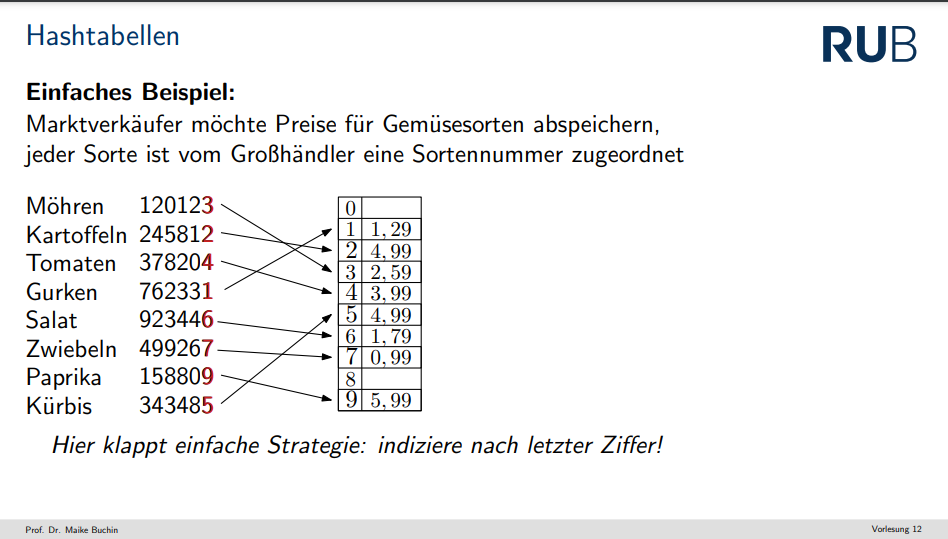
Hier können wir ein "Tolles" beispiel sehen, wie man hashtabellen anwenden kann
leichzeitig können wir aber auch sehen, wie "einfach" kollisionen passieren können
Dementsprechend suchen wir jetzt ein paar wege mit denen man Kollissionen vermeiden / umgehen kann
Dafür gibt es verschiedene Lösungsansätze
Hashing mit Verketting
Hashing mit offener Addressierung (in der VL stehen hier noch die englischen namen, aber ich glaube ihr seit schlau genug, dass ihr das auch so kapiert weil naja, englisch ist irgenwie nen requirement)
Gleichzeitig müssen wir uns überlegen welche Hashfunktion am besten passt
Passt für unsere Anwendung besser eine einfache, aber individuelle
oder eine (warscheinlich kompliziertere) universelle Hashfunktion
Wenn wir bei jedem Index, also jeder Zelle in der Hashtabelle eine Verkettete Liste speichern, können wir mehrere sachen auf einmal speichern, die den selben Hashwert haben
Jedes element e wird dann dementsprechend in der Liste in t[h(e)] gespeichert.
Das ding hat dann logischer weise auch wieder einige operationen
Find
remove
insert
build
Alle "access" funktionen durchsuchen die Folge
Da stellt sich die Frage, ob es Hashfunktionen geben kann, die eine Kleine bzw. kurze Liste garantieren
Leider gibt es das nicht, da wir nicht garantieren können, dass der "letzte" schlüssel gegrabbled wird
Wir folgern, dass wir linearen Platzbedarf und konstante erwartete Ausführungzeiten der Operationen durch m=Θ(n) erreichen.
Dabei passen wir dann die Tabellengröße an, so wie wir das schon bei unbeschränkten arrays gesehen haben