Rechnerarchitektur Zusammenfassung
Eine schriftliche Zusammenfassung des Faches Rechnerarchitektur aus dem Wintersemester 2022/23 von Tobias Rempe im Studiengang Angewandte Informatik (PO20) der Ruhr Universität Bochum.
- Aufbau
- Moore's Law
- Dennard Scaling
- Multicore und Amdahl's Law
- In Anderen Aspekten der Prozessortechnik
- Höhere Sicht eines Rechners.
- Modellierung eines RISC-Rechners
- Modellierung eines CISC-Rechners
- Virtueller Rechner
- Übersetzung versus Interpretation
- Performanzmaße eines Rechners
- Kernbegriffe:
- Hardware VS Software
- Exkurs: Hardware / Software Co-Design
- Prinzipieller Aufbau eines Rechners
- John von Neumann (1903-1957)
- Der Arbeitsspeicher (Hauptspeicher)
- Der Prozessor (+ Cache)
- Register des Prozessors
- Prinzipielle Arbeitsweise eines Prozessors
- Ebenensicht : The SQL
- Assembler Höhere Programmiersprachen
- Befehlssatz
- Klassen von Befehlen
- Wofür steht RISC-V?
- Wat is das überhaupt
- Die verschiedenen Register
- Arithmetische Befehle
- Beispiele für Systembefehle
- Datentransportbefehle
- Adressierungsarten
- Unterprogramme
- Instruktionskodierung
- Assembler Maschinenschprache
- Verarbeitung einer Instruktion (RISC-V)
- Aufbau eines RISC-V Prozessors
- CISC - Complex Instruction Set Computer
- RISC - Reduced Instruction Set Computer
- RISC VS CISC
- Designprinzipien für Rechner
- Wat dat überhaupt?
- Speedup
- Hazards
- Out of Order Execution
- Datenabhängigkeiten
- Out-Of-Order-Execution
- Modifikation Registerbank
- SRAM
- DRAM
- Aufbau von Zellfeldern
- Funktionsweise des RAM
- Gründe für Komlexe Speicheroganisation
- Lokalitätsprinzip
- Speicherorganisation Heute
- Big Endian vs Little Endian
- Caches
- Mittlere Zugriffszeit beim Lesen
- Aufbau eines Caches
- Cache als assoziativer Speicher
- Was passiert mit Alten daten?
- Direct Mapped Cache
- Prinzipielle Funktionsweise: Schreibzugriff
- Festplatte (Hard Disk Drive)
- Alternative: Solid State Disk (SSD)
- Das problem mit dem Hauptspeicher
- Segmentierung
- Übersetzung von virtuellem Speicher auf physikalischen Speicher
- Meltdown
- Spectre V1
- Spectre V2
- Formen der Parallelität
- Amdahl's Law
- Formen der Parallelverarbeitung auf prozessor-/ Rechnerebene(1)
- Beispiele für parallele Rechnerarchitekturen:
- Verbindungsstrukturen
- Modellierung von Verbindungen
- Beispiele für parallele Rechnerarchitekturen
- Grafikprozessor
- Aber wie funktioniert das eigentlich?
- Die Schritte in der Grafikpipeline:
- Klassifikationsmerkmale bei Parallelen Rechnerarchitekturen
- Klassifikation nach Flynn [1966]
- Motivation?
- ASCII
- Unicode
- Definition: Code
- Probleme bei Binär-encoding:
- Fehlererkennender Code
- Beweis Lemma [Fehlerkorrektur]
- 1-Fehlerkorrigierender Code
- Hamming code
- Memory - I/O Busse
- Heutige Bussysteme
- Morgige?
- Selbstaktende Codierung
- Prinzipieller ablauf einer Kommunkation
- Direct memory Access
- Optionen eines Busses
Turingmaschine
Aufbau
- Hat ein unendlich langes Band
- Hat einen Schreib- und Lesekopf
- und das Programm was das steuert
- Zustände
- So wenn A passiert dann mach B und gehe in zustand C
- In der Theorie kann man damit alles Berechenbare Berechnen
The Law's
Moore's Law
- Besagt dass sich die Transistordichte jedes Jahr verdoppelt
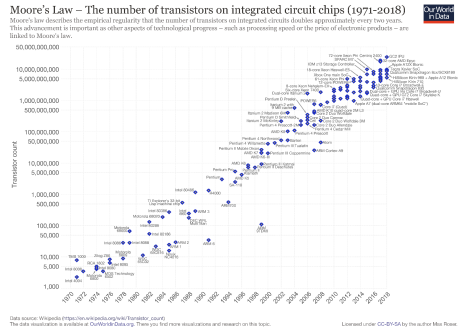
- Allerdings wurden die Bestandteile dann irgendwann so klein, dass es physikalisch nicht mehr möglich war / nicht mehr sein wird alles so eng zusammen zu quetschen, weswegen morees law immer irrellevanter wird
- Es wird kontinuierlich schwerer Moores law einzuhalten
- Wir sind jetzt schon im faktor 15 hinterher
- Zudem kommen immer mehr herausforderungen hinzu
- Absturz ist also vorprogrammiert
- Wir müssen also etwas tun!
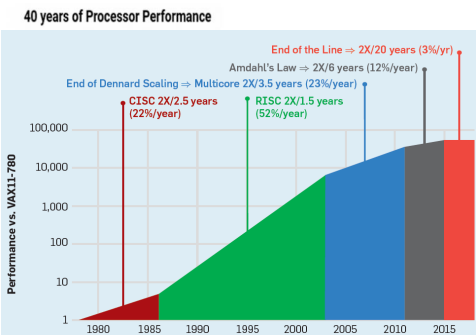
Dennard Scaling
- Besagt, dass wir trotz steigender Transistordichte einen Konstanten Energieverbrauch erwarten sollen
- Da lag er aber leider falsch der Bre
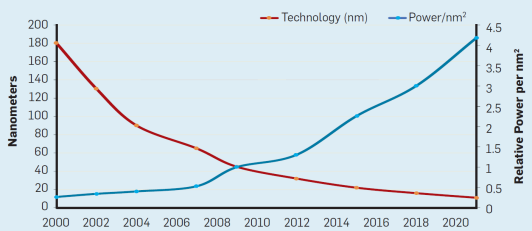
- Wie wir sehen haben wir die Energieeffizienz kontinuierlich gesteigert
- Deswegen nur bis knapp 2000 anwendbar
Multicore und Amdahl's Law
- Neue Prozessoren haben mehrere Prozessorkerne, damit arbeit paralellisiert werden kann
- Allerdings ist hier der Performancegewinn begrezt, da nicht alle Programme paralellisiert werden können
- Dementsprechend ist immer der Langsamste teil ausschlaggebend für die Geschwindigkeit des Programms
In Anderen Aspekten der Prozessortechnik
- Wir entwickeln immer mehr Flexiblere Sachen
- Wie man z.b. auch an handys sieht, die immer effizienter und schneller werden.
Rechnersichten
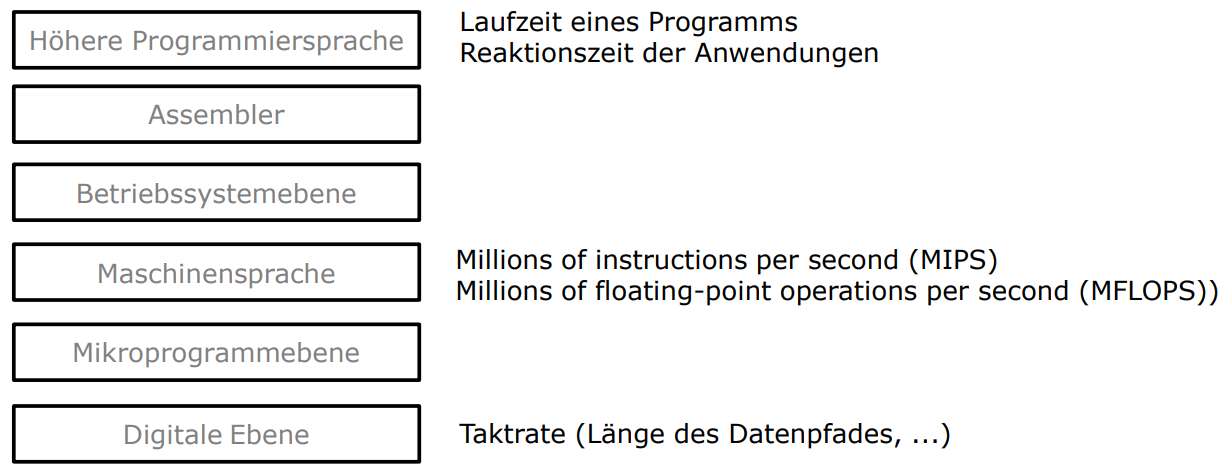
Höhere Sicht eines Rechners.
- Wenn wir uns als Programmierer einen Rechner anschauen sehen wir einen schwarzen kasten der das macht was wir von ihm wollen
- Es gibt dementsprechend verschiedene Wege Einen Rechner zu sehen, und daher auch verschieden "genaue" Sichtweisen
- Am besten stellen wir das mit sog. Schichtenmodellen da.
- Diese sind der Abstraktion nach geordnet, also die "einfachste" ebene ist die ganz oben, und die technischste ganz unten
Modellierung eines RISC-Rechners
(RISC = Reduced Instruction Set Coputer)
Verschidene Ebenen und Sprachen
- "Höhere" Programmiersprachen 99% des Marktanteils
- C++, Java, Fortran, Rust
- Assembler
- Symbolische Notation der bisher vorhandenen Befehle direkt an den Computer
- Betriebssystemebene
- "Hintergrunddienste" wie Speicherorganisation, Dateiverwaltung etc.
- Maschinensprache
- Die unterste Sprache an die wir so dran kommen
- Befehle sind folgen von 0, 1 also Stromimpulsen
- Digitale Ebene
- Also die Hardware Direkt
Modellierung eines CISC-Rechners
(Complex Instruction Set Computer) Bekanntester Vertreter x86 bzw. x86_64
Verschiedene Sprachen und Ebenen
- Ein CISC Rechner bitete anstelle von "normalen" Instruktionen die in hardware Augewertet werden den sog. Mikrocode.
- Mit diesem ist es möglich Komplexere Instruktionen wie mini-programme im Prozessor zu realisieren, sodass sie virtuell ohne kosten ausgeführt werden können und somit wie "in hardware laufen" ohne extra hardware zu konzipieren.
- Dise Mikroprogramme sind aus direkten Instruktionen für das Steuerwerk zusammengesetzt und so vergleichbar mit einem "regulären programm", was allerdings tiefer im Prozessor aufbewahrt, und somit deutlich schneller evaluiert und ausgeführt werden kann..
- Dadurch ist deutlich flexiberes Prozessorendesign möglich
Virtueller Rechner
- Jede Ebene ist ein "virtueller Rechner" , zu dem eine Sprache gehört.
- Programme der Sprache werden
- Übersetzt in die Sprache übersetzt oder
- In die Sprache Interpretiert
- Die Virtuelle Maschine trollt den benutzer einfach richtig hart und tut so, als würden die Programme die er in geschrieben hat einfach direkt auf Hardware ausgeführt werden
Hirachie: Illustriert

Übersetzung versus Interpretation
Übersetzung
- Ein Compiler ist eine Software die einfach nen Programm was in der Sprache geschrieben wurde nimmt, da nen bissl drauf rum haut und dann ein equivalentes Programm ausspuckt welches in der sprache "geschrieben" wurde ausspuckt.
- Wenn dann die maschinensprache, also das Binärformat ist, sprechen wir von einem -Vollcompiler
Ausführung eines -Programms
- Wir Trainsformieren das originale Programm in ein äquivalentes -Programm
- Dann führen wir dieses massiv krasse -Programm aus, nich?
Interpretation
- Dat funktioniert nach einem Festen Schema, und das sieht so aus:
Abwägung
- Interpreter sind einfacher zu Implementieren als Compiler
- Deswegen auch oft einfacher auf andere Plattformen zu Übertragen
- geeignet für z.b. Prototypen von Programmiersprachen
- Compilation ist leider nicht immer möglich
- Compilierte (Übersetzte) Programme sind aber (fast) immer schneller als interprätierte Programme
- Es kann Codeoptimierung @ Compiletime verwendet werden
- Und Binäranweisungen werden von hardware ausgewertet und sind dadurch radikal schneller
- (vollständige) Compilation ist allerdings auch nicht immer erwünscht
- Da das zu einer Systemabhängigkeit führt, und deswegen nicht einfach auf andere Systeme übertragen werden kann
Performanzmaße eines Rechners
Rechnerorganisation: Aufbau und Funktionsweise
Kernbegriffe:
- Hardware
- Ja die hardware halt, dein Handy, dein PC, dein dummes Mainboard was vor 3 jahren mal nen stromschlag bekommen hat und deswegen immer weiter failed und deine smartwatch
- Software
- Das was die meissten Entwickler schreiben, also der kram der auf deinem Gerät läuft
- Firmware
- Der "kleber" der die verbindung zwischen Software und Hardware herstellt, also sowat wie das BIOS.
- Meisstens in ROM (Read only Memory) gespeichert
Hardware VS Software
- viel von dem was früher in Software gemacht werden musste kann heute in hardware gemacht werden
- z.b. Ganzzahlige Multiplikation, Division, Floatingpointarithmatic
- Allerdings gibt es auch neue Konzepte wie das oben genannte RISC-Konzept
- Hier wird wieder mehr in Software ausgeführt
- Damit das Instruktionsset so simpel wie möglich gehalten werden kann, um schnelle Übersetzung und Ausführung zu garantieren
- z.b. Ganzzahlige Division
- Hier wird wieder mehr in Software ausgeführt
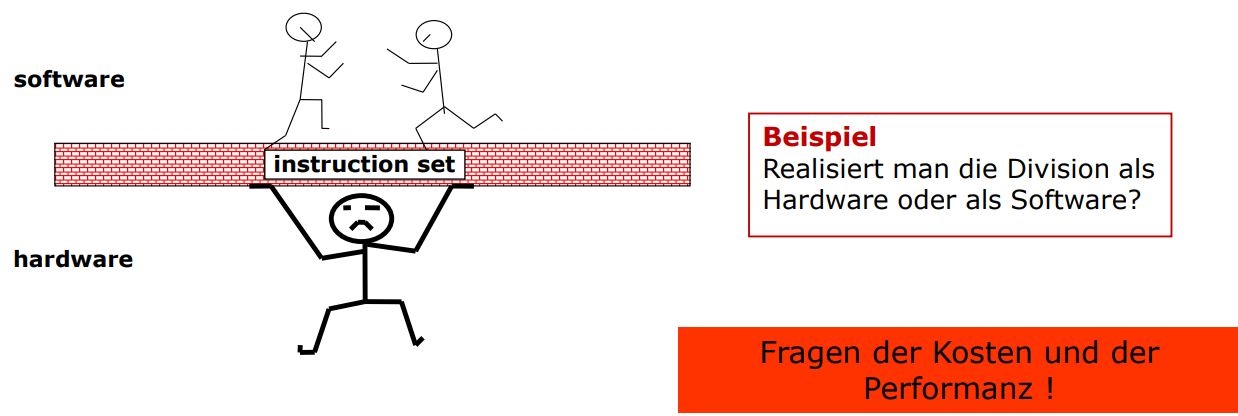
Der Kram zwischen Software und Hardware
- Das instruktionsset (Instruction-Set)
- Dieses Set bestimmt den befehlssatz mit dem später (wie der name schon sagt) Befehle an den Computer gesendet werden können
- Dieses set entscheidet was in hardware direkt gelöst werden kann, und was nur in software gebaut werden kann
- Hier ist es wichtig alles genau abzuwägen, weil es zu ineffizienzen und problemen führen kann wenn wir alles in eine richtung schieben.
Exkurs: Hardware / Software Co-Design
- Es gibt auch Orte an denen wir sehr spezifische goals haben und die erreichen müssen
- z.b. Smart-Home geräte
- Die dinger nennt man dann Embedded Devices
- Die müssen ja am ende nicht frei programmierbar sein, deswegen können wir die hardware auf genau diese eine sache die die erledigen müssen zuschneiden
- Sowas wurde z.b. auch bei alten videospielkonsolen gemacht
- Die müssen ja am ende nicht frei programmierbar sein, deswegen können wir die hardware auf genau diese eine sache die die erledigen müssen zuschneiden
- Was in Software und was In hardware implementiert wird muss ein sog. "Systemarchitekt" entscheiden, der dann anforderungen Stellt.
- Die genaue Implementation wird dann (halb-) automatisch durch diverse Laufzeitanalysen erprobt und Entschieden
- Aber insgesamt sollte alles was in software schwer ist weil es z.b. sehr rechenintensiv ist auf Hardware ausgelagert werden
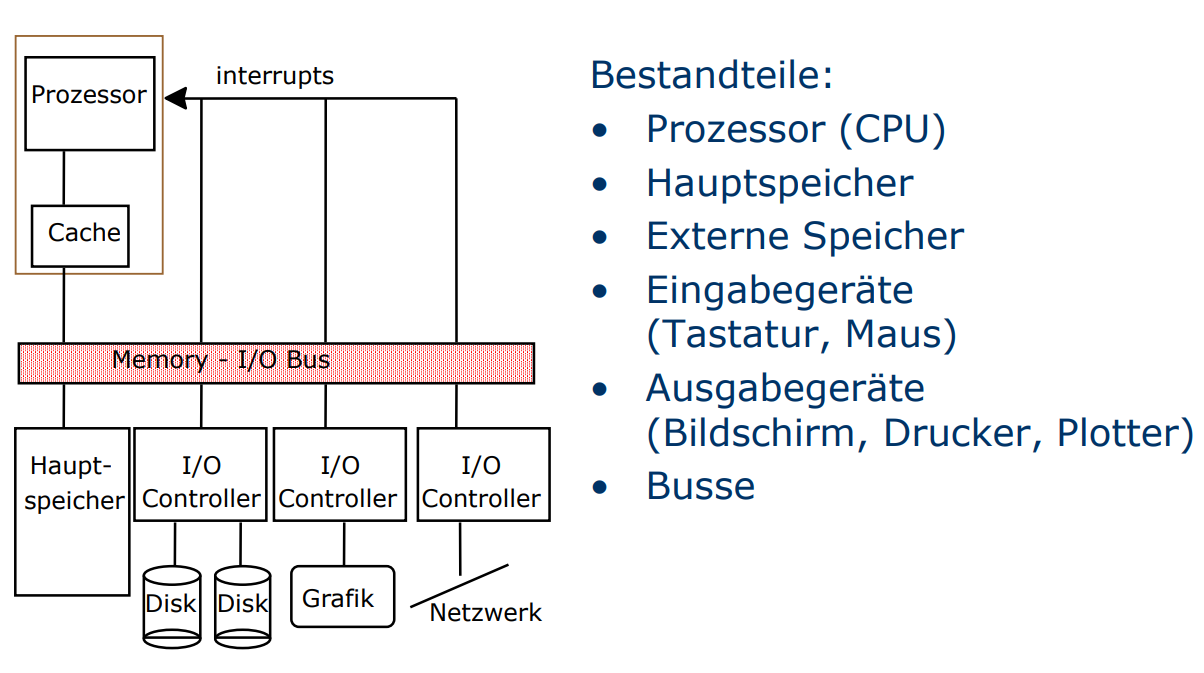
Prinzipieller Aufbau eines Rechners
John von Neumann (1903-1957)
(es geht weiter mit Geschichte!!1!)
Der bre hat den aufbau von Modernen Rechnern sehr stark beeinflusst, u.a. weil er einfach nen krasser Mathematiker war
Das sog. von-Neumann-Prinzip was (schocker) er erfunden hat beruht auf den folgenden 4 Punkten:
- voll-elektrischer Rechner
- binäre Darstellung der Daten
- Benutzung einer Arithmetischen Einheit
- Benutzung eines Steuerwerkes
- Interner Daten- und Programmspeicher
Falls ihr in der 1. Klasse aufgepasst habt merkt ihr, dass das da 5 Punkte sind. SUPER GEMACHT! 3 Bonus Gummi-Punkte!
Der Arbeitsspeicher (Hauptspeicher)
- Ja in dem ding können wir sachen speichern an denen wir gerade arbeiten (ja was nen wunder nich)
- der besteht aus (also praktisch beliebig vielen) Speicherzellen
-
Eine Speicherzelle
- speichert immer Information bestehend aus Bit. wird dabei die Wortbreite des Speichers genannt.
- kann 8, 16, 32, 64 oder noch viel mehr Bit groß sein
- Allerdings arbeiten unsere Modernen rechner und geräte fast Exklusiv mit 64Bit Großen 's
- Hat eine Adresse mit der sie identifizierbar ist.
- Diese liegt im bereich
- Nix kann kleiner sein als Wortbreite, also ist eine speicherzelle die kleinste adressierbare einheit des speichers
- speichert immer Information bestehend aus Bit. wird dabei die Wortbreite des Speichers genannt.
Der Prozessor (+ Cache)
Dat ding besteht in seiner Einfachsten Form aus
-
Steuerwerk (Control Unit)
- indem das ding die richtigen Signale an die richtigen Sachen schickt bewegt sich der nächste Maschinenbefehl aus dem Hauptspeicher in eins der Arbeitsregister im Cache
- Dann sendet der noch mehr von diesen Signalen um die gelesene Maschineninstruktion auszuwerten
- Dann führt er diese Instruktion durch das senden weiterer Signale aus
-
Recheneinheit (Arithmethic Logic Unit - ALU, Datenpfad)
- führt die Teilschritte (Vergleiche, Move, Addition, etc.) gemäß der Signale aus.
-
Registerbank
- Beinhaltet die sog. Register
- Die dinger speichern daten die der Prozessor in diesem Moment benötigt
- Denn auf Register kann ohne Wartezyklus direkt vom Rechenwerk aus Zugegriffen werden
Register des Prozessors
- Hier werden die sachen aufbewahrt, die schnell vom Prozessor gebraucht werden
| Art der Information | Speicherort | Name | Acronym |
|---|---|---|---|
| aktuell abzuarbeitender Befehl | Befehlsregister | Instruction Register | IR |
| Adresse des als nächstes abzuarbeitenden Befehl | Befehlszähler | Program Counter | PC |
| Adresse im RAM ab der Daten gespeichert werden können | Stackpointer | Stackpointer | SP |
| von der ALU zu verarbeitende Daten | Arbeitsregister | General Purpose Register | GPR |
Prinzipielle Arbeitsweise eines Prozessors
-
Fetch-Decode-Execute-Zyklus
-
Fetch
- Hol dir den nächsten Maschinensprachebefehl aus dem GPR und speicher ihm im IR a. Die benötigte Adresse steht im PC
-
Decode
- Analysiere (Decode) die daten und lade dir alle wat du gerade brauchst
-
Execute
- Führ dat wat de dir da zusammen gesucht hast aus und speicher dat erjebnis ab (im Hauptspeicher)
-
REPEAT!
-
Assembler
- Der kram ist die letzte ebene vor 1en und 0en
- Befehle sind meist elemetare operation (also so simpel wie es geht)
- Du hast die Register für datenmanipulation, damit du damit halt arbeiten kannst nich
- Operanden werden durch verschiedene Adressierungsarten bestimmt
- Wir verweisen zurück auf die Ebenenansicht
- wir schauen uns die jetzt nochmal genauer an
Ebenensicht : The SQL
- Höhere Programmiersprachen
- C++, Java, Fortran, Rust, Son kram
- Assembler
- symbolische Notation der bisher vorhandenen Befehle
- Betriebssystemebene
- zusäzliche util Dienste wie Speicherorganisation, Dateiverwaltung
- Maschinensprache
- unterste frei zugängliche Sprache Befehle sind am ende Folgen über 0 und 1
- Mikroprogrammebene
- Instruktionen zum setzen von Steuersignalen
- Hier werden die Instruktionen in Maschinensprache auseinander genommen und in die Steuersignale übersetzt
- digitale Ebene
- die eigentliche Hardware
Assembler Höhere Programmiersprachen
| Assembler | Höhere Programmiersprachen |
|---|---|
| Zusammenhang ist oft schwer erkennbar | Man kann den Code (meisstens) gut lesen und funktionen dem kontext entnehmen |
| Einfache Befehle | Komplexe Sprachkonstrukte |
| Direkter Speicherzugriff und volle Kontrolle | Konstruktion komplexer Datentypen und limitierte Kontrolle |
| Maschinenabhängige Programme | Programme die weitgehend unabhängig von Maschinen sind |
Befehlssatz
Der Befehlssatz eines Prozessors wird beim Entwurf festgelegt
- Kompromiss:
- Wünsche aus Anwendersicht
- Technische Machbarkeit
- Von bedeutung sind dabei
- Bitbreite zur kodierung eines Befehls
- Also wie viel platz ein Befehl verbrauchen soll
- und im Umkehrschluss auch wie viele Befehle verwendet werden können
- Zusätzliche Adressierungsarten von Befehlen
- Bitbreite zur kodierung eines Befehls
Klassen von Befehlen
Da gibts janz viele, wir betrachten hierbei z.b.. sowas wie
- Arithmetische Befehle (Rechnen-Dinger)
- Add, Sub, Mult, Div, Srl, ...
- Datentransportbefehle (Ja dinger zum Daten transportieren halt)
- Load, Store, Move, Push, Pop, I/O, ...
- Logische Befehle (Halt so dings dinger zum vergleichen)
- And, Or, Not, ...
- Bitverarbeitende Befehle (So zeuchs was iwas iwo rein schreibt)
- Setzen, Rücksetzen von bits, Statusflags, ...
- Sprungbefehle (So GEH ZU BEFEHL 210,7 BRE!!!!!)
- Systembefehle (Ja du da fällt mir gerade kein Beispiel ein)
Exkurs: RISC-V
Wofür steht RISC-V?
- Reduced
- Instruction
- Set
- Computer
- 5
Wat is das überhaupt
- Eine Modulare 32/64/128-Bit RISK Architektur
- Basisinstruktionen RVd ()
- Dazu gibt es Optionale Instruction-Set-Extentions (Befehlssatzerweiterungen) u.a:
- RVd: Multiplikation & Division
- RVd: Floating-Point Arithmetic mit einfacher , doppelter und vielfacher Genauigkeit
- LOAD/STORE-Architektur:
- Es kann lediglich durch LOAD- bzw. STORE-Befehle auf den RAM zugegriffen werden
- Alle anderen Befehle müssen mit den Registern auskommen
Die verschiedenen Register
- 32-Bit Datentyp, hat eine kapazität von "einem Wort"
- Konventionen legen fest, wie diese Register heißen und wie sie verwendet werden sollen:
- 12 Register für Variablen des Quellprogramms:
- 7 Register für temporäre Variablen:
- Allerdings müssen diese Konventionen nicht zwingend beachtet werden
- Derartige Konventionen sind aber notwendig, wenn mehrere, potentiell getrennte, Programmteile zusammen laufen können
| Register | Name | Verwendung |
|---|---|---|
| Konstante 0 | ||
| Rücksprungadresse | ||
| Stackpointer | ||
| Globaler Pointer | ||
| Threadpointer | ||
| - | - | Temporäre Register |
| / | Registerzwischenspeicher oder Framepointer | |
| Registerzwischenspeicher | ||
| - | - | Funktionsargumente und Rückgabewerte |
| - | - | Funktionsargumente |
| - | - | Registerzwischenspeicher |
| - | - | Temporäre Register |
- Beschränkte Anzahl von Registern
- Diese sind leider unzureichend um die Variablen von "echten" Programmen aufzunehmen
- Deswegen müssen größere, oder größere Mengen von Variablen (z.B. Arrays) im Speicher abgelegt werden.
Arithmetische Befehle
- Befehle für Festkommaarithmetik (RV32 )
- mit oder ohne Vorzeichen
- Befehle für Gleitkommaarithmetik (RV32 )
- Im prozessor integriert
- Emulation durch Zerlegung in elementare Operationen
- Vergleichsbefehle
- Schiebe und Rotationsbefehle
Rechenbefehle
| Instruktion | Operation | Resultat |
|---|---|---|
| ADD , , | Add | |
| ADDI , , | Add immediate |
- Analog dazu gibt es SUB
- Andere Assemblersprachen lassen auch Speicherinhalte als Operanden zu (z.b. Einige CISC Sprachen)
Vergleichsbefehle
| Instruktion | Operation | Resultat |
|---|---|---|
| SLT | Set less than | |
| SLTU | SLT unsigned |
Schiebebefehle
| Instruktion | Operation | Resultat |
|---|---|---|
| SLL | Shift left logical | |
| SRL | Shift right logical | |
| SRA | Shift right arithmetic |
Notation: kann Register oder Immediate sein
Ladebefehle
| Instruktion | Operation | Resultat |
|---|---|---|
| LUI | Load upper immediate | |
| LW | Load word | |
| LB | Load byte |
Speicherbefehle (Memory)
| Instruktion | Operation | Resultat |
|---|---|---|
| SB | Store byte | |
| SW | Store word |
Logische Befehle
| Instruktion | Operation | Resultat |
|---|---|---|
| AND | And |
- BITWISE OR
- Analog dazu OR, XOR (Exclusive Or)
Sprungbefehle
- Werden verwendet um den ablauf von Programmen zu steuern
- Klassifikation
- bedingte / unbedingte Sprungbefehle
- Sprung erfolgt relativ zum Programmzähler oder absolut
- Unterprogrammaufrufe (wie Subroutines oder so)
- Rückker zum aufrufenden Programmabschnitt (wie beim ende einer Subroutine)
- Nennt man auch "unterprogrammbeendigung"
- Unterbrechung (Interrupt)
- bedingte / unbedingte Sprungbefehle
Unbedingte Sprünge: (pc: Program Counter)
| Instruktion | Operation | Resultat |
|---|---|---|
| JAL | Jump and Link | , Sprung zu |
| JALR | JAL Register | JAL zu Adresse |
Bedingte Sprünge
| Instruktion | Operation | Resultat |
|---|---|---|
| BEQ | Branch Equal | Sprung, falls |
| BNE | Branch not Equal | Sprung, falls |
| BLT | Branch Less Than | Sprung, falls |
| BGE | Branch Greater Equal | Sprung, falls |
| BLTU | Unsingned BLT | Sprung, falls |
| BGEU | Unsingned BGE | Sprung, falls |
Systembefehle
In RISC-V
| Instruktion | Operation |
|---|---|
| ECALL | Systemaufruf |
Control-/Statusregister (CSR):
| Instruktion | Operation |
|---|---|
| CSRR{W|S|R} | Lese bzw, überschreibe Control- und Statusregister |
- Dat gut für
- Fehlerbehandlung(Exceptions)
- das Steuern vom Prozessorverhalten
Beispiele für Systembefehle
Rechenbefehle
| Bedeutung | RISC-V Instruktion |
|---|---|
- Längere Ausdrücke müssen vom Anwender bzw. dem Compiler in eine Reihe von einfacheren operationen aufgeteilt werden
- Wenn nötig kann man auch temporäre Variablen einführen
- Befehl
- Annahme: Variable befindet sich im Register , im Register , im Register und im Register . Das Ergebnis soll im Register gespeichert werden.
(# Ist hier der Kommentar-Operator)
Logische Befehle
Sprungbefehle
- C/C++ Programm:
if (i == j) {
f = g + h;
} else {
f = g - h;
}
- RISC-V Assembler-Programm:
Annahmen: Variablen in
- Hier sind und Labels (Sprungmarken) zu denen gesprungen werden kann
Anderes Beispiel:
Annahmen: Variablen in Ebenso: Basisadresse von in

Datentransportbefehle
Annahme: ist ein Array vom Datentyp Wort. Die Variable steht im Register , die Basisadresse von steht im Register
Datentransportbefehle
- Transport von Daten zwischen Quelle und Ziel
- Quelle und Ziel sind entweder im Hauptspeicher oder in den Registern
- Übertragung ist auch zwischen den I/O-Schnitstellen und Registern möglich
- Zudem ist Transport nicht wirklich das Richtige Wort, Weil eigentlich nicht wirklich viel von der Quelle entfernt wird
Adressierungsarten
(Keine RISC-V Befehle)
- Implizite Adressierung
- Dat Ziel wird durch den Befehl bestimmt
- Dat Ziel wird durch den Befehl bestimmt
- Unmittelbare Adressierung
- Operand wird als Wert angegeben
- Operand wird als Wert angegeben
- absolute (direkte) Adressierung
- Operand ist Inhalt der angegeben Adresse
- Operand ist Inhalt der angegeben Adresse
- indirekte Adressierung
- Operand ist Inhalt des Zeigers an der angegeben Adresse
- Operand ist Inhalt des Zeigers an der angegeben Adresse
- indizierte Adressierung
Unterprogramme
(Subroutines oder so)
- Prinzipieller Ablauf, wie kann man sich dat vorstellen
- Der Kontrollfluss wird an eine Subrutine abgegeben
- Diese Prozedur macht wat sie machen soll
- Und dann wird der Kontrollfluss zurück an die aufrundende Funktion geworfen
- RISC-V-Unterstützung für Prozeduraufrufe
- es gibt ein spezielles Register für die Sicherung der Rücksprungadresse:
- Sprunginstruktionen
- (Jump and Link)
- Speichert die Rücksprungadresse in und springt dann zur Adresse der Subroutine
- (Jump Register)
- springt zur Adresse, die im angegebenen Register steht, d.h. springt zurück zum aufrufenden Programm
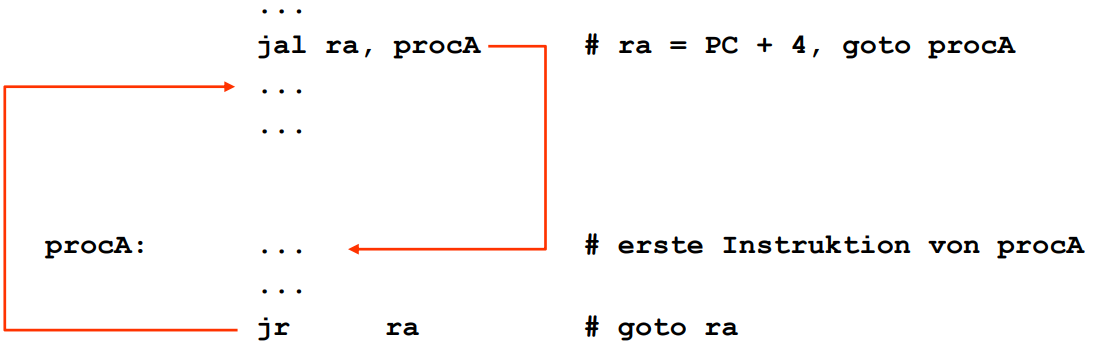
- (Jump and Link)
- Prozeduren brauchen im Allgemeinen Argumente und leifern Resultate
- Dafür gibt es in RISC-V folgende Konvention:
- 8 Register für Argumente
- 2 Register für Resultate
- Dafür gibt es in RISC-V folgende Konvention:
Beispielprogramm:
Gegeben: Wert in Register , Rückgabe in

Instruktionskodierung
- Wir haben bisher die Instruktionen "nur" in Assemblersprache notiert, der Prozessor versteht den kram aber leider so garnich
- Detwegen müssen wir iwas aus dem kram machen, was der Prozessor verstehen kann.
- Was kann der verstehen? genau! binär, deswegen müssen wir dat jz binär kodieren
- Das nennt man (... Trommelwirbel) Instruktionskodierung (Wasn Schocker)
add
- Bei RV32 sind alle Instruktionen 32 Bit lang!
- Da die ganzen Instruktionen allerdings verschieden viele Operanden haben, gibt es verschiedene Instruktionsformate:
- R-Typ
- I-Typ
- S/B-Typ
- U/J Typ
- Da die ganzen Instruktionen allerdings verschieden viele Operanden haben, gibt es verschiedene Instruktionsformate:
Instruktionsformat R-Typ
Instruktionsformat R-Typ (Register-Format) wird für Arithmetische Instruktionen verwendet

Instruktionsformat I-Typ
Das Immediate-Format wird verwendet für
- Immediate-Versionen der arithmetischen und logischen Instruktionen
- Load-Instruktionen und Systembefehle

- ist eine signed 12-bit Zahl im 2er Kimplement und kann dadurch Werte zwischen und annehmen
- Beispiel:
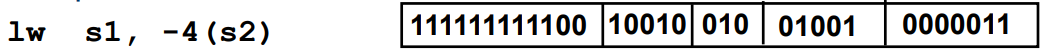
Instruktionsformat S/B-Typ
Das Store-Format wird, wie man sich wohl schion denken kann, für Store-Befehle verwendet

- offset ist eine signed 12Bit-Zahl auf die der Wert aus Register addiert wird um die effektive Speicheradresse zu bekommen

Beim B-Typ - also Branch-Format für bedingte Sprünge - gibt es eine andere interpretation der offset bits
Instruktionsformat U/J-Typ
Das Upper-Format wird für Spezielle Load-Befehle verwendet

- ist eine 32-Bit Zahl deren 20 höchstwertige Bits
[31:12] ins Register geladen werden
Beim J-Typ, also unbedingten Sprüngen wird die effektive Sprungadresse aus [20:1] (interpretiert als signed 20-bit Zahl) konstruiert
Assembler Maschinenschprache
| Assembler | Maschinensprache |
|---|---|
| Symbolische Bezeichnung von Befehlen, Adressen (label) und teils der operanden | Binäre Darstellung von Befehlen (Op-Code) Adressen und Operanden in einem Datenwort |
| Ein-/Ausgabe-Routinen eines etwaigen betriebssystems könenn verwendet werden | Bibliotheken für komplexe Befehl(sketten) |
| Programme müssen vor der Ausführung assembliert (also zu Maschinensprache übersetzt) werden | Programmen werden direkt ausgeführt, da wir praktisch eine "binary" von hand schreiben |
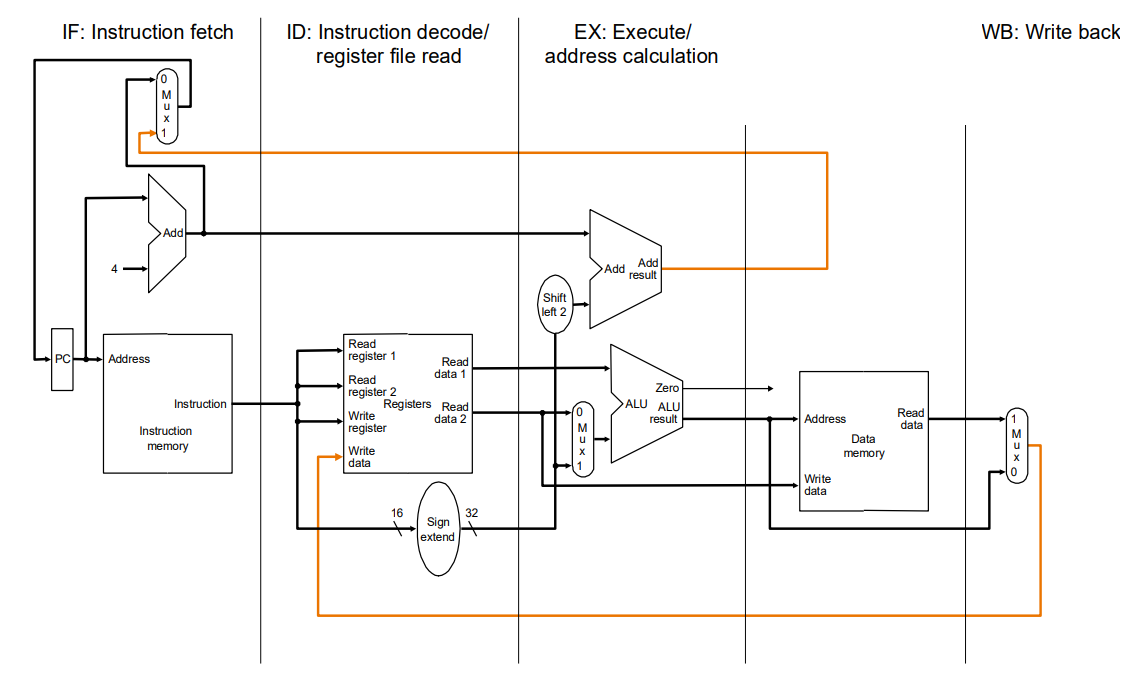
Verarbeitung einer Instruktion (RISC-V)
- Im Folgenden bereits um Pipelining erweitererte CPU
- Pipelining kommt später
- Die verarbeitung läuft Stufenweise
- Wir holen uns den befehl
- Decoden den kram erstmal / Holen uns den Operanden
- Befehl ausführen
- Speicherzugriff (wenn wa wat schreiben oder lesen wollen)
- Ergebnis in Register schreiben
- Hier ist zu beachten, dass es je nach prozessor anders aussehen kann
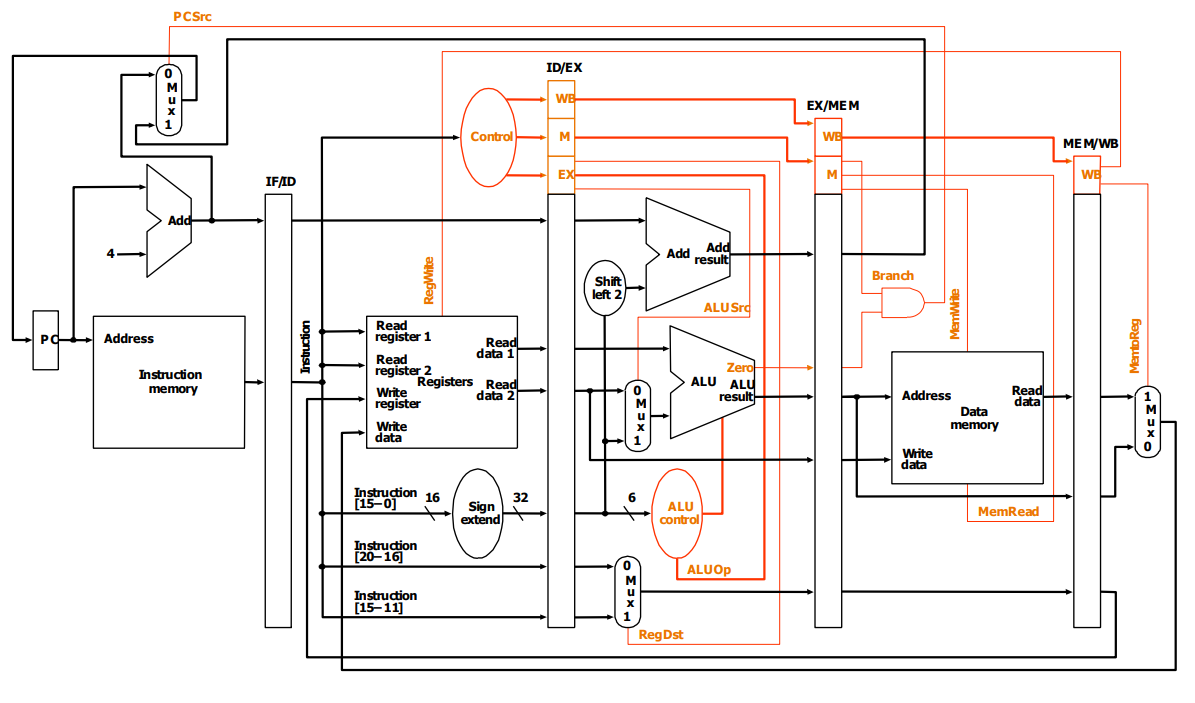
Aufbau eines RISC-V Prozessors
Befehlssätze und Optimierungen
Die Extreme:
CISC-Rechner und RISC-Rechner
CISC - Complex Instruction Set Computer
- Großer Satz von Maschinenbefehlen
- Diese können teilweise sehr Spezifische und Komplexe operationen selbstständig ausführen
- Sehr unterschiedliche Ausführungszeiten, also nicht wirklich regelmäßig
- Das system wird durch ein sog. Mikroprogramm im Prozessor gesteuert, nicht durch direkte Hardware.
- Zudem war der erste "moderne" Rechner (IBM 369) ein CISC-Rechner
Was spricht für CISC?
- Komplexe Befehle schliessen eine Lücke zwischen den programmiersprachen und der hardware
- es gibt "direktere" übersetzungen
- Komplexe Befehle verringern den Ramverbrauch, da alles praktisch "vorprogrammiert" ist und nicht erst in viele kleine operation zerbrochen werden muss
- Dadurch kann es auch zu einem geschwindigkeitsboost kommen, da weniger auf den "langsamen" Speicher zugegriffen werden muss
- Komplexe befehle können vom Compiler einfacher aus geschriebenem programmcode hergeleitet werden
- Je mehr der Computer in hardware / intern Regeln kann, desto zuverlässiger "ist" er, denn hardware ist angeblich zuversichtlich
- Ist allerdings nicht ganz richtig, da fehler die hier auftreten, fast nicht zu beheben sind ohne neue hardware zu beschaffen
Was spricht dagegen?
- Viele Programmspeicher-Zugriffe können aufgrund von Cache strategien sehr schnell und effizient ausgeführt werden
- Dementsprechend brauchen wir keine "riesiegen" mikroprogramme
- Hardware ist, wie oben schon gesagt, nicht zuverlässiger als Software, zum großen teil auch wegen der fehlenden debugging-möglichkeit
- Die komplexen befehle die der compiler "einfach" nutzen könnte werden von modernen Compilern kaum noch genutzt, da sie oft sehr spezifisch sind und gewisse hardware voraussetzen
Eine Statistik für CISC-Rechner (ca.1990)
Wenn wir uns CISC Rechner anschauen, denken wir an die Intels und AMDs auf dieser Welt, irgendwie klar weil sie die einzigsten firmen auf der Welt sind die die x86 Architektur verwenden dürfen, die, wie oben erläutert, die weit verbreiteteste CISC Architektur die wir haben ist.
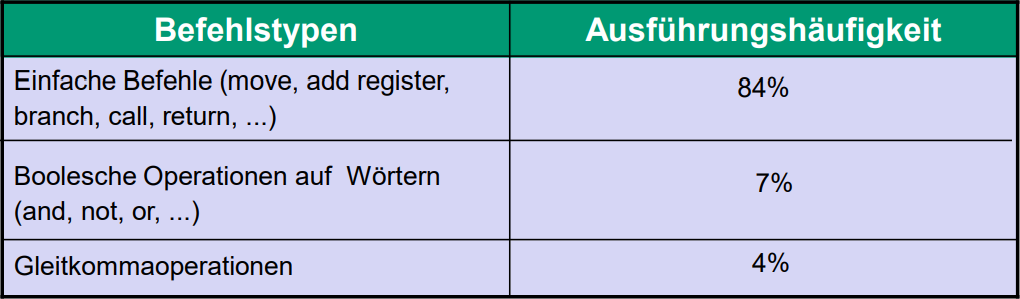
Wenn wir uns obige Statistik anschauen, sehen wir, dass mehr als 90% aller Operationen die ein x86 (oder auch x86, x86_64 (auch bekannt als AMD64 weil AMD als erste Firma einen funktionierenden 64-Bit prozessor bauen konnte)) ausführt "einfache" Befehle sind, die nicht weiter heruntergebrochen werden können und deswegen auch direkt in Hardware gehandled werden könnten. Da dies bei CISC allerdings nicht passiert, wird effizienz auf dem tisch liegen gelassen, um die restlichen ~10% zu supporten.
RISC - Reduced Instruction Set Computer
- Einfache Befehle
- Deswegen ein insgesamt kleinerer Befehssatz
- Jeder Befehl ist in einem Verarbeitungsschrit ausführbar
- Effizienz durch berechenbarkeit
- großer interner Registersatz
- Leistungsfähige Speicherhirachie
- Dadurch, dass das System nicht mehr durch Mikrocode Kontrolliert wird, kann ein Fest verdratetes Steuerwerk verwendet werdn
- Dadurch wird das System schneller und effizienter, einfach weil Hardware in so ziemlich jedem fall schneller ist als software.
Bekannte Beispiele für RISC-Prozessoren sind
- Mips R2000/3000 (1982-89)
- IBM Power
- IBM PowerPC
- Apple M
- Apple A
- Apple T
- Quallcomm Snapdragon
RISC VS CISC
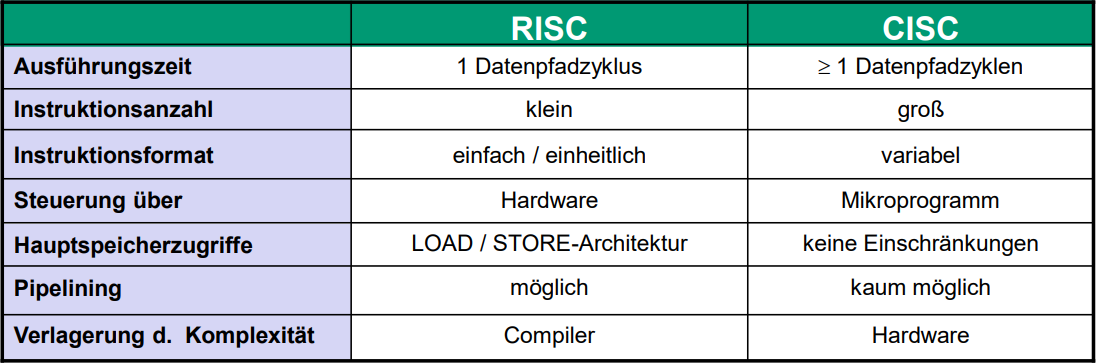
Man sieht hier vor allem, dass RISC was Zyklen / Operation angeht um einiges Effizienter agiert als CISC in vergleichbaren fällen.
Ein Großes Element ist natürlich auch der Unterschied zwischen Hardware und Software als ausführungsplattform, da Hardware logischerweise um einiges schneller und effizienter ist.
Hier mal ein paar konkrete beispiele:
-
Power PC (IBM, RISC)
- Operanden aus dem Hauptspeicher kommen nur von load-, store-, branch- oder cache-Befehlen vor
- Drei Modi der Adressberechnung:
- Registerinhalte + Konstante
- Summe zweier Register
- Registerinhalt
-
Pentium 4 (Intel, CISC)
- Mögliche Operanden für beliebige Befehle
- Konstante (natürlich nicht für Ergebnisse)
- Registerinhalt
- Speicherplatz
- I/O Port
- Adressberechnung:
- Speicheradresse = Segment + Offset
- Segment steht in einem speziellen Register
- Offset wird entsprechend der folgenden Tabelle berechnet
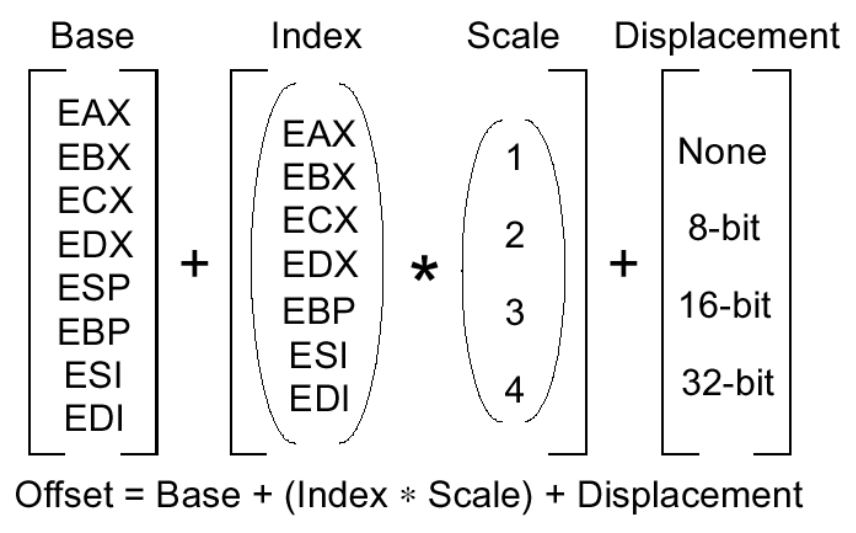
- Mögliche Operanden für beliebige Befehle
Designprinzipien für Rechner
- Was sind die Schlüsseloperationen für das was wir bauen wollen
- Wie soll der Datenpfad aussehen? (also dat rechenwerk + die Verbindungen zum RAM etc.)
- Was brauchen wir für Maschinenbefehle in dieser Architektur.
- Wie können wir dafür sorgen, dass alles was wir brauchen möglichst in Hardware und ohne mikroprogramme in einem Zyklus ausführbar ist
- Wie können wir den Befehlssatz erweiterbar machen, aber so, dass bei erweiterung die Maschine nicht langsamer wird
Pipelining
Wat dat überhaupt?
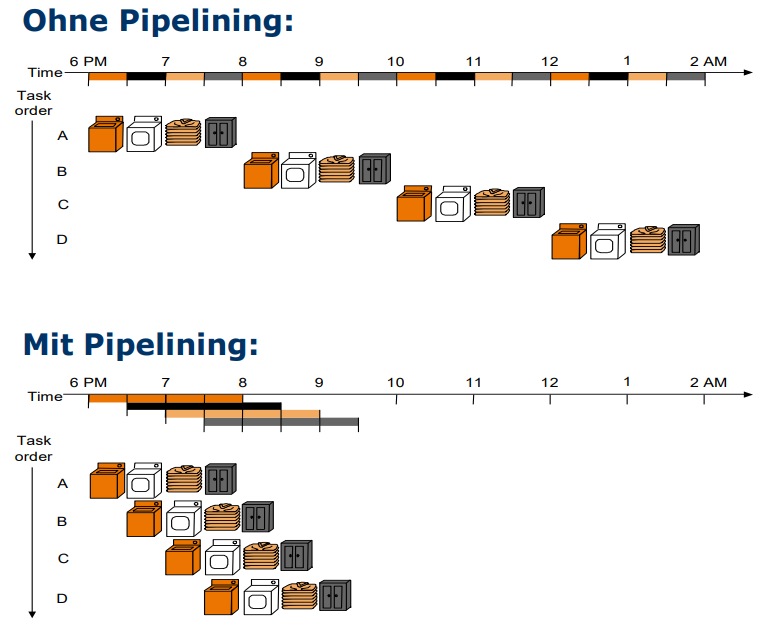
Wir visualisieren uns dat mal mit nem massiv coolen Beispiel:
Wir kommen nachhause und finden einfach nen riesigen haufen Wäsche die AUF EINMAL dreckig geworden ist.
Nun Reflektieren wir mal darüber, wie wir die wäsche wieder sauber bekommen. Unserer normaler Workflow ist wie folgt:
- Wir nehmen die Dreckige Wäsche und stecken sie gewaltsam in die Waschmaschine die dann etwa 30 Minuten Läuft
- Wir werfen die gewaschene Wäsche in den Trockner der dann ebenfalls wieder 30 Minuten läuft
- Dann müssen wir die Kleidung Bügeln und falten, was wieder etwa 30 Minuten dauert
- Und zuletzt müssen wir unsere nun wieder saubere Wäsche nehmen und sie in den schrank räumen.
Wir werfen einen Blick auf den unmöglich großen Berg an plötzlich dreckiger wäsche und realisieren, dass dat nich alles in unsere Waschmaschine passt. Wir müssen sogar warscheinlich insgesamt 4 Mal waschen. Das dauert, wenn wir alles hintereinander machen, ja knapp 8 Stunden. Das ist nicht so gut, und genau hier kommt pipelining ins spiel!
Denn wenn wir mehrere Verschiedene Arbeitsschrotte auf einmal bzw. gleichzeitig erledigen können reduzieren wir die zeit von etwa 8 auf 3 Stunden Reduzieren!
Wie wir das machen zeigt dieses Bild:
Das ist ja alles Schön und gut, aber wie machen wir das Im computer?!
- Damit wir Pipelining im Datenpfad anwenden können müssen wir die abarbeitung der diversen Maschinenbefehle in mehrere teilschritte (Phasen) aufteilen die idealerweise alle die gleiche dauer haben.
- Bei der Aufteilung ist vor allem der bestehende Befehlssatz und die zur verfügung stehende Hardware zu beachten, da die beiden elemente genau aufeinander abgestimmt sein müssen, wenn wir ein effizientes system entwickeln wollen.
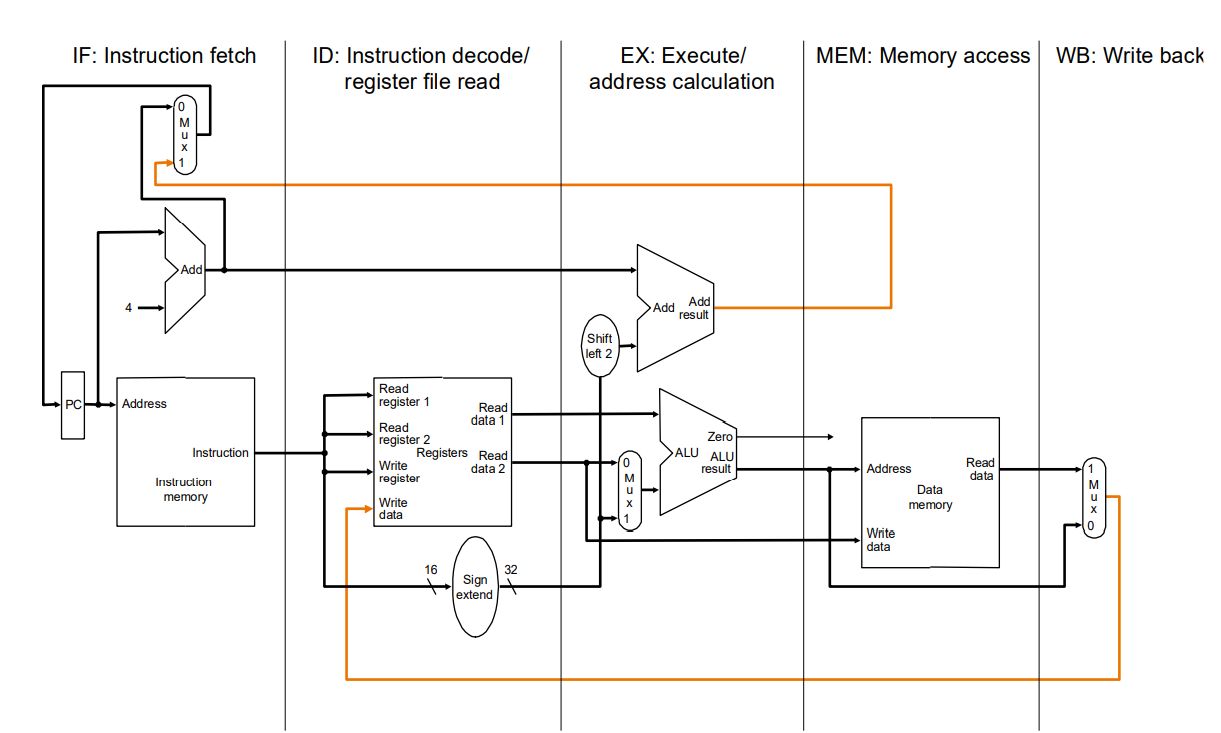
- Hier ein Beispiel für die Abarbeitung in 5-Schritten:
- Befehl-Holphase, auch bekannt als Instruction-Fetch
- Dekodierungsphase, hier lesen wir die Operanden aus Registern
- Ausführung / Adressberechnung, hier führen wir den befehl aus und berechnen wo wirs hin speichern müssen
- Speicherzugriff, hier wird alles gelesen was wir vom Speicher wollten
- Abspeicherphase (result write back phase) Hier schreiben wir alles zurück in den speicher, was wir berechnet haben
- Bei CISC Pipelinig ists schwierig die genaue dauer zu bestimmen, da mikroprogramme in der Dekodier und Ausführungsphase unterschiedlich lang brauchen können und die komplexität sehr unterschiedlich sein kann
Hier ein Beispiel wie man den Datenpfad aufteilen kann:
Speedup
- Annahmen:
- Abarbeitungszeit eines Befehls ohne Pipelining:
- wir haben pipelinestufen mit gleicher lauftzeit der Stufen
- Laufzeit einer Stufe ist also
- Beschleunigung Bei ausführenden Instruktionen
- Laufzeit mit pipeline =
- Laufzeit mit Pipeline =
- Beschleunigung um Faktor
Laufzeit mit Pipeline:
Laufzeit ohne Pipeline:
Beschleunigung um:
Ergebnis:
für nähert sich der Speedup also der Anzahl der Pipelinestufen
Es wurde vorausgesetzt, dass sich die Ausführung der BEfehle ohne weiteres aneinanderreihen ("verzahnen") lässt. Dies ist in der Praxis mit immer der Fall Hazards
Hazards
Massiv krasse Gefahren würd ich mal sagen (boah krass dat hat sich ja sogar gereimt)

Hier tritt ein Problem auf! Denn wenn pipelining verwendet wird kann es sein, dass der ADD Befehl in diesem Beispiel nicht auf den Wert in R1 zugreifen kann wenn man die Pipeline nicht stoppt
Dat kann man lösen indem man NOPs einfügt, also No-Operation
Ein NOP könnte erspart werden, wenn der load befehl direkt am ende der Execute-Phase das ergebnis im angegebenen Register zur verfügung stellt. Allerdings ist dafür extra Hardware von nöten
Bedingte Verzweigung: Control Hazards
Sprungbedingungen werden potentiell zu spät ausgeführt, da durch das pipeling schon die nächste Instruktion abgearbeitet wird
Mögliche Lösung: Branch Prediction
- Mit branch Prediction Raten wir praktisch, was als nächstes kommt
- Natürlich raten wir nicht vollständig sondern agieren auf bisherigen erkenntnissen
- Wir springen also basierend auf unserer Spekulation durch die gegend
- Und falls wir uns mal vertun leeren wir die pipeline wieder auf den vorherigen stand wenn wir dann "zurücksetzen"
Zusammenfassend
- Wir können unsere Schnelligkeit in den Pipelines steigern, indem wir Branch Prediction oder Forwarding und Optimierung der Instruktionen verwenden, allerdings kann das auch zu Hazards führen die unterm strich unsere Schnelligkeit verringern
Out of Order Execution
| In Ohrder Execution | Out of Order Execution |
|---|---|
| Es wird sich strickt an den Programmcode gehalten und alles wird sequenziell ausgeführt | Prozessor bestimmt die ausführungsreihenfolge und optimiert "on the fly" mit möglichen Fehlern |
| Vorab-analyse von Datenabhängigkeiten und Datenfluss | Fortlaufende Datenabhängigkeitanalyse zur Laufzeit |
| Warten auf "langsamere" Befehle | Kein warten, alles was unabhängig bearbeitet werden kann wird dann einfach vorgezogen |
| Leistungseinbußen | Schnelligkeit erfordert zusätzliche Hardware, kann zu unvorhersebaren Risiken führen |
Datenabhängigkeiten
-
Read-after-Write (RAW)
- bzw. True Dependence
- Instruktion liest Wert aus Register, das in beschrieben wurde
-
Problem:
- Zugriff auf veralteten Registerwert
 -Die lö
sung hier: Wir müssen mit der Ausführung Warten, bis wir den richtigen wert haben.
-Die lö
sung hier: Wir müssen mit der Ausführung Warten, bis wir den richtigen wert haben.
-
Write-after-Read (WAR)
- bzw. Anti-Dependence
- Instruktion schreibt Wert in Register, das in gelesen wurde

-
Problem
- ggf. haben wir aufgrund der Veränderten Ausführungsreihenfolge den falschen Wert.
- Lösung hier: ALten wert Zwischenspeichern und das Register umbenennen (Also einfach ein anderes Verwenden)
-
Write-after-Write (WAW)
- bzw. Output Dependence
- Instruktion schreibt Wert in Register, das in beschrieben wurde

-
Problem:
- Hier ist ggf auch der falsche wert aufgrund der veränderten Ausführungsreihenfolge
- Die Lösung sieht hier ähnlich aus, wir nennen die Register um bzw. verwenden andere Ressourcen
Out-Of-Order-Execution
- Erlaube, dass RAW unabhängige Instruktionen langsame "überholen" können
- Mehrere Funktionseinheiten verwenden um die Execute-Phase zu Pararellisieren
- Scheduler ein, der Instruktionen ihrer geschwindigkeit und aktuellen Prozessorauslastung scheduled und ausführt.
- Hierfür verwendet man dann einen "Warteraum" für die nach hinten verlegten Instruktionen
Data-Driven-Execution-Graph
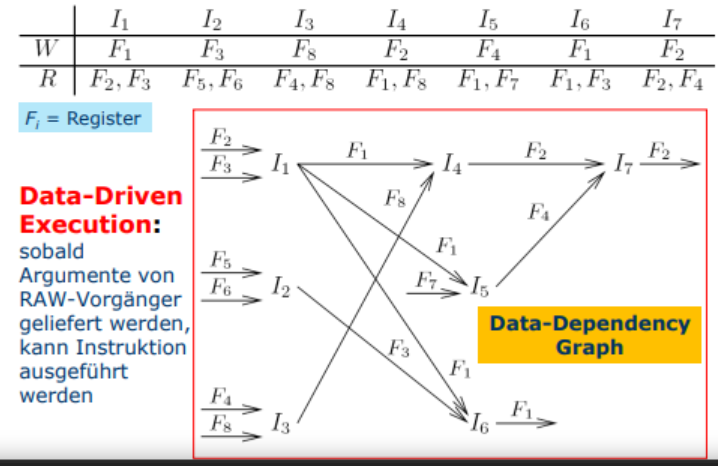
Modifikation Registerbank
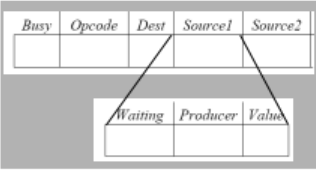
- Pro Register zusätzliche Felder Busy und Producer.
- Busy: Eine instruktion I in FU die gewisse instruktionen in dieses Feld schiebt
- Producer: (nur relevant falls Busy-Flag gesetzt): Eindeutiger Name dieser Instruktion
- Als namen werden Paare (j, k) mit folgender Bedeutung verwendet:
- Diese instruktion wurde zur Dispatchzeit in SlotJ des Warteraumes der Funktionseinheit Allokiert
- Schreibenden Zugriff auf Register erhält bei gesetztem busy flag nur der dort eingetragene Producer. SObald dieser schreibt wird das busy flag resetted
Struktur dieser "Warteräume"
- Busy: Dieser Slot ist besetzt
- Opcode der auszuführenden Instruktion
- Dest Das zielregister für das Ergebnis der Instruktion
- Source1 werden Kopiert aus den zur Dispatchzeit vorliegenden einträgen für die Source.Register
- Wenn der Wert des Register aktuell berechnet wird, ist die Waiting flag gesezt, und der Produzent des Wertes Eingetragen
- Data-Driven-Execution: Nur wenn beide Waiting Flags nicht gesetzt sind, kann die Instruktion ausgeführt werden
Verteilung der Ergebnisse
- FU legt Dest, Producer, Value auf Common data bus
- Alle FUs hören mit, und schauen ob in einem Warteslot auf diese Producer-Daten gewartet wird
- Wenn ja: Wird das waiting flack zurückgesetzt und der Wert übernommen
- Registerbank lässt den schreibzugriff auf Destination nur zu, wenn keine busy flag gesetzt ist und der genannte Producer mit dem Producer aus dem Common data bus übereinstimmt
Speicheradressierung
- Speicher wird mit Byteadressen adressiert
- Speicher ist praktisch ein Riesiges eindimensionales Array von Bytes
- Adresse einer Speicherzelle entspricht dem Array Index
- Logischerweise (looking at you, Lua) startet das Array bei 0, also ist dat auch die niedrigste Speicheradresse
- Wie wird ein Wort (4 Byte / 32-Bit) im Speicher abgelegt?
- Das höchstwertige Byte des Wortes speichert sich an der niedrigsten Byte adresse
- Ein wort wird mit der Adresse seines höchstwertigsten Bytes adressiert (also da wo es losgeht)
- Wortadressen müssen ein vielfaches von 4 sein ("Alignment Restriction")
SRAM
-
Static Random Access Memory
- Ja halt statischer speicher für einen bit
- Gleicher aufwand für lesen und schreiben
- Die information wird im status der inneren Transistoren gespeichert
- Vorteile:
- ist sehr schnell
- Braucht keine regelmäßige Auffrischung
- Nachteil:
- Physisch relativ groß im gegensatz zu DRAM
DRAM
-
Dynamic Random Access Memory
- Information wird in der Ladung eines Kondensators gespeichert
- Vorteile:
- Einfacher Aufbau
- Geringe Größe
- Nachteile
- höhere Zugriffszeit
- kondensator verliert mit der zeit seine ladung
- braucht daher einen periodischen refresh
Aufbau von Zellfeldern
- 2-Dimensionale Matrix
- mehrere Speicherzellen Speicherzeile
- Mehrere Speicherzeilen Speicherfeld/Zellenfeld
- Mehrere Speicherfelder
- 1 Speicherbank
- Mehrere Speicherbanken
- 1 Speicherchip
Funktionsweise des RAM
- Ansprechen von Ziel chip/bank
- Speichercontroller der CPU übermittelt die Adresse
- Entschlüsselung durch Zelendecoder
- Aktivierung der Speicherzeile (wordline)
- Spaltendecoder ermittelt die richtige Position
- Bitline wird mit Datenleitung des speicherchips verbunden
- Lesen: Zustand des Kondensators wird ausgelesen
- Schreiben: Richtiger Zustand wird gesetzt
- Deaktivierung der Speicherzelle
Gründe für Komlexe Speicheroganisation
- Ein Zugriff auf eine Hauptspeicherzelle ist langsamer als ein Zugriff auf ein Register
- Hautpspeicherzellen sind DRAM-Zeilen (dynamische speicherzellen), wärend Register in der Regel SRAM-Zellen (statische Speicherzellen) sind
- Bei einem "simplen" registerzugriff kommt man sogar ohne Bus-operation aus!
- Idee: man stellt dem prozessor einfach einige megabyte Register zur Verfügung
- Aber:
SRAM-Zeilen sind wesentlich größer als DRAM-Zellen
- Aber:
- Leider ist das derzeit noch nicht realistisch, das kann aber vielleicht in der Zukunft kommen.
Lokalitätsprinzip
- Lokalitätsprinzip:
- Programme greifen sehr schnell hinterinander auf einen relativ kleinen Teil des Adressraums zu
- Temporale Lokalität
- Wenn ein Zugriff auf eine Adresse erfolgt, wird auf diese Adresse mit "großer" Wahrscheinlichkeit bald wieder zugegriffen
- z.b. beim Abarbeiten von schleifen
- Wenn ein Zugriff auf eine Adresse erfolgt, wird auf diese Adresse mit "großer" Wahrscheinlichkeit bald wieder zugegriffen
- Räumliche Lokalität
- Wenn ein Zugriff auf eine Adresse erfolgt, werden mit "großer" Watscheinlichkeit bald Zugriffe auf in der nähe liegende Adressen erfolgen
- z.b. Verarbeiten von Arrays, Loopen durch Listen
- Wenn ein Zugriff auf eine Adresse erfolgt, werden mit "großer" Watscheinlichkeit bald Zugriffe auf in der nähe liegende Adressen erfolgen
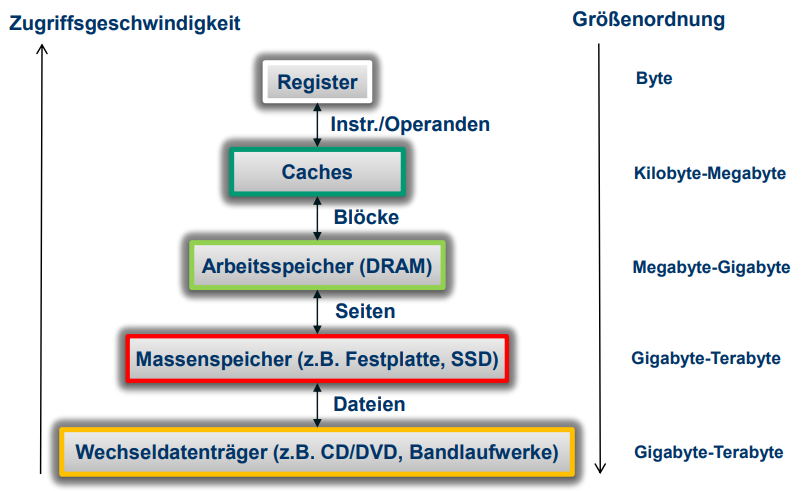
- Aufgrund der Lokalität kann man Speichersysteme hierarchisch aufbauen
- Obere Stufe der Hierarchie: schneller und teurer Speicher (wenig)
- Untere Stufe der Hierarchie: Langsamer und billiger Speicher (aber viel davon)
Speicherorganisation Heute
Big Endian vs Little Endian
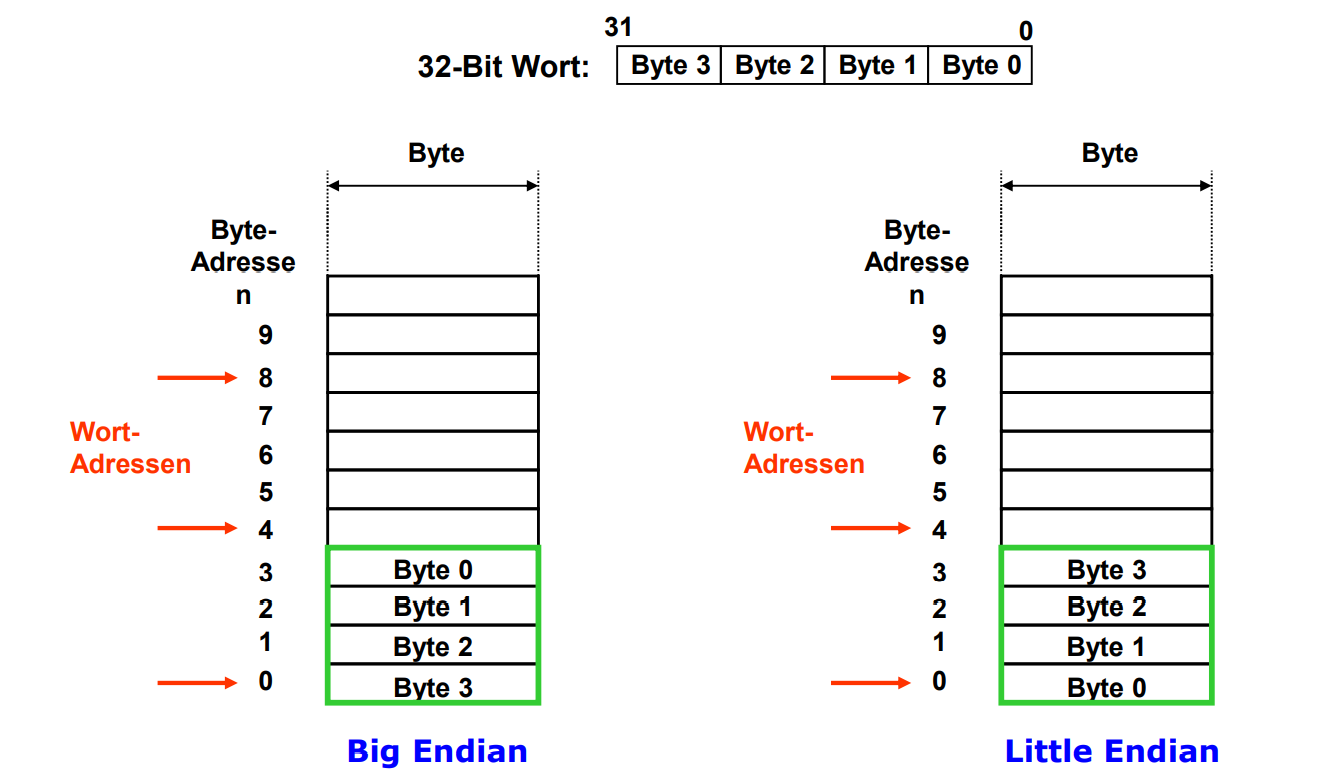
Caches
- Cache kommt aus dem Französischen cacher (verstecken)
- Er kann durch ein Anwendungsprogramm nicht explizit adressiert werden
- Der kram ist "software-Transparent", d.h. der benutzer muss eig nich wissen, dass es den kram gibt
Lage des Caches
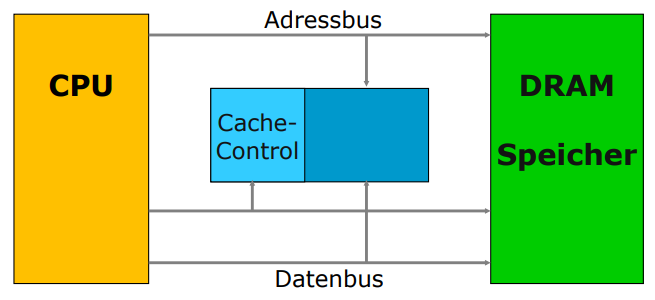
In der Regel besitzt ein Rechner getrennte Caches für Instruktionen (Instruktionscache) und für Daten (Datencache)
Ziel des Cache Einsatzes
- Wir versuchen die daten so "nah wie möglich" zu halten
- Prozessor kann dann mehr auf Caches zugreifen und verschwendet weniger zeit beim warten auf den langsamen RAM oder auf den unglaublich langsamen langzeitspeicher
- Hierfür müssen wir das oben angesprochene Lokalitätsprinzip verwenden
Wie sieht das in der Praxis aus?
Wenn der CPU die daten die er sucht in dem Cache findet, dann ist er glücklich und macht einfach weiter ohne zu warten
Sei das aber nicht so schön, muss der CPU erstmal auf den Arbeitsspeicher zu und schreibt das was er gelesen hat gleichzeitig in den cache, und in die arbeitsregister der CPU
Mittlere Zugriffszeit beim Lesen
- Zugriffszeit des Caches
- Zugriffszeit beim Hauptspeicher
- Trefferrate
- Durchschnittliche Zugriffszeit:
Aufbau eines Caches
- Ein Cache besteht aus zwei Speicher-EInheiten, die wortweise einander fest zugeordnet sind,
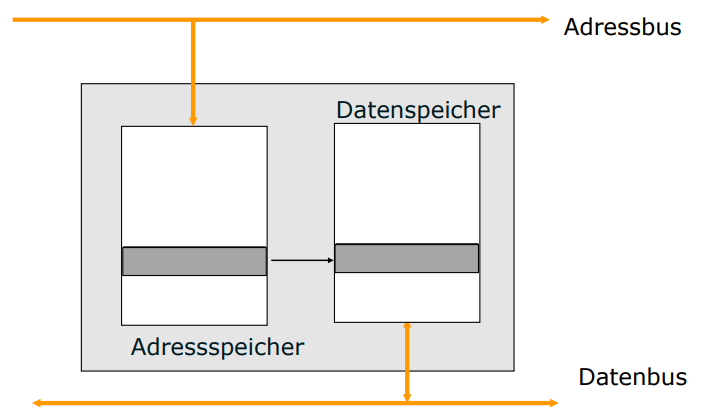
Cache als assoziativer Speicher
- Im idealfall, wäre Cache immer Inhaltsorientiert, also assoziativ
- Die von dem Prozessor angelegte Adresse wird parallel mit allen im Adresspeicher des Caches vorhandenen Adressen verglichen
- Außerdem kann ein neues Datenteil praktisch an jeder freien Stelle des caches abegelgt werden.
- Deswegen gibt es eine Aufwendige Logik für den Parallelen Vergleich
- Assoziative Speicher nur für kleine Cache-größen
Was passiert mit Alten daten?
- Wenn wir cachedaten nicht mehr brauchen, dann müssen wir sie wegwerfen um platz für neues zu machen.
- Wenn wir noch nen register frei haben, nutzen wir immer erst das, einfach weil das uns den job einfacher macht und wir nicht 500 Sachen abfragen müssen
- Wenn aber nix mehr frei ist, dann schauen wir nach einigen Kriterien
- Least Recently used (LRU) wirft das weg was am längsten nicht benutzt wurde
- Least Frequently Used (LFU) wirft dat wech, auf das am wenigsten zugegriffen wird
- First in, First out (FIFO) Wirft das über bord, wat schon am länchsten da war
Direct Mapped Cache
- Die von der CPU angelegte Adresse wird in 2 Teile Gespalten
- Die niederwertigen Bits adressieren einen EIntrag im Adresspeicher
- Dieser Eintrag wird dann mit den höherwertigen Bits der Adresse verglichen
- Speicherzellen des Hauptspeichers, deren niederwertige Stellen gleich sind, werden auf die gleiche Position im Cache abgebildet
Illustration
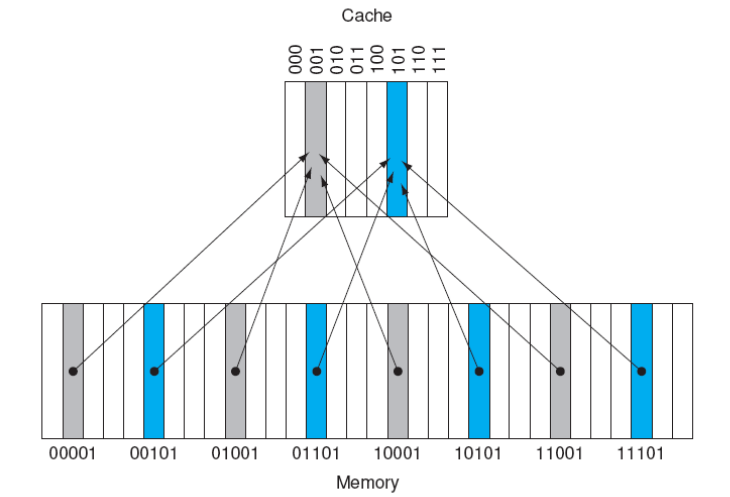
-
Cache Tag
- Der Index (Cacheblockadresse) kann nicht eindeutig der Speicherblockadresse zugeordnet werden
- Also ist der Inhalt des Caches an dieser position somit nicht eindeutig bestimmbar
- Deshalb verwendet man die restlichen bits der Speicherblockadresse für einen sog. "Tag"
- Zu jedem block im Cache speichern wir auch den Tag
- Wir finden jetzt also daten, indem wir die caches nach dem Tag und dem Eintrag suchen
-
Valid bit
- Ja nen bit was sagt, ob der eintrag valid is
- Am anfang (und nach jedem flushen) enthält der cache keine gültigen daten
- Also ist das Valid bit 0
- Wenn wir dann aber einen validen eintrag hinzufügen, wird das bit auf 1 gesetzt
- Am anfang (und nach jedem flushen) enthält der cache keine gültigen daten
- Ja nen bit was sagt, ob der eintrag valid is
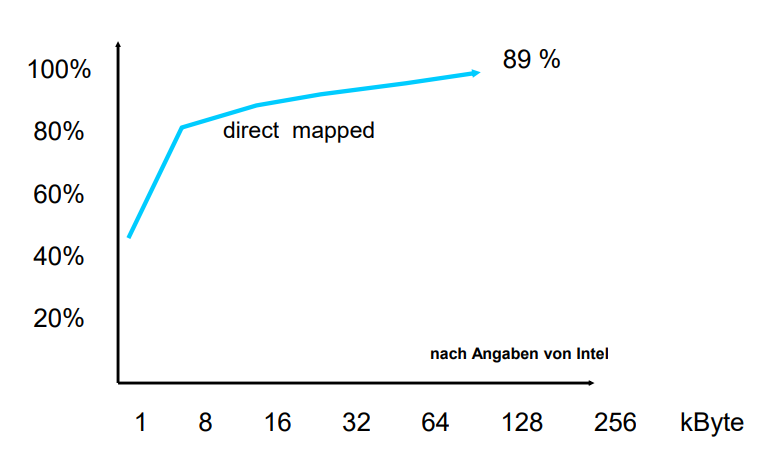
Hier sehen wir, wie viele Anfragen im cache gehittet werden können, gemessen an der cachegröße
Prinzipielle Funktionsweise: Schreibzugriff
- Schreibe Datum in den Arbeitsspeicher unter Adresse :
- CPU Überprüft, ob eine Kopie der Hauptspeicherzelle a im Cache abgelegt ist
-
Write-through verfahren
- cache miss: CPU schreibt das Datum in die Hauptspeicherzelle mit der Adresse . Der Inhalt des Cache wird nicht verändert
- cache hit: die Kopie der Haauptspeicherzelle im Cache wird aktualisiert, die Hauptspeicherzelle wird auch direkt aktualisiert
- so kann sich der Prozessor auch direkt anderen sachen widmen, aber der speicher-controller regelt das update im ram, ohne dass der Prozessor warten muss
-
Write-back Verfahren
- cache miss: CPU schreibt das datum in die Hauptspeicherzelle mit Adresse , Der Inhalt des caches wird nicht verändert.
- cache hit: Die kopie der Hauptspeicherzelle im Cache wird aktualisiert und durch "dirty bit" als verändert markiert. Die hauptspeicherzelle selbst wird erst später aktualisiert, nämlich erst wenn die Kopie ausm cache geworfen wird, die CPU damit also "fertig" ist
-
write-allocation Verfahren
- cache miss: CPU schreibt Datum in den Cache (markiert mit "dirty bit"), aber nicht in den Hauptspeicher, da wirds dann wie oben erst aktualisiert, wenns ausm cache geworfen wird
- cache hit: Wie beim write-back verfahren
Writeback VS writeallocation
Vorteile von Write-back/Write-allocation
- Schreibzugriffe auf Cache bei cache hit ohne Wartezyklus möglich (bei write-allocation sogar bei cache miss)
- Belastung des Systembusses kleiner, wenn das Rückschreiben in den Hauptspeicher erst nach mehreren Schreibvorgängen erfolgen muss
Nachteile von Write-back/Write-allocation
- Schwierikeiten bei der Datenkonsistenz, wenn andere Komponenten die daten brauchen die nicht auf den CPU-Cache zugreifen können
Festplatte (Hard Disk Drive)
- ja dat ding hat halt mehrere Platten
- Die haben jeweils ihren eigenen lese/schreibkopf
- und dann funktioniert dat maßgeblich wie ne CD
- Sind aufgeteilt in Sektoren von 128Byte bis 1 Kbyte
- Und haben dann auch diverse Spuren & Schreibdichten
Adressierung
- Heute verwenden wir das sog. Logical block addrssing, oder LBA
- Hierbei sind die Sektoren fortlaufend numerriert
- Und ein Festplattencontroller übersetzt in physikalische Koordinaten des Sektors
Partitionierung
- Festplatten kann man aufteilen in diverse Partitionen
- Wie eine partition aufgebaut aussieht, steht im ersten Sektor im "master boot record" (MBR) oder den äußeren 32 Sektoren (GUID Partition Table, GPT) in einer sog. Partitionstabelle
-
MBR: 4 Master-Partitionen, je 16 Byte
- Erster und letzter Sektur in CHS-Koordinaten (je 3Byte)
- Erster Sektor in LBA und Gesamtzahl Sektoren (je 4Byte)
- allg. Informationen (Typ/Format, bootfähig; je 1 Byte)
- Maximale Partitionsgröße: Abhängig vom System
- Maximale Festplattengröße: Abhängig von Systemarchitektur
- MBR: Enthält vorwiegen Bootstrap-Code zum Laden des Betriebssystems (wird von BIOS/UEFI beim Start geladen und ausgeführt)
Ausführung eines Festplattenzugriffs
- Beweg die Köpfe zu dem Richtigen Zylinder
- Warte bis der gesuchte Sketor zum Kopf rotiert
- Übertrage den Inhalt des Sektors
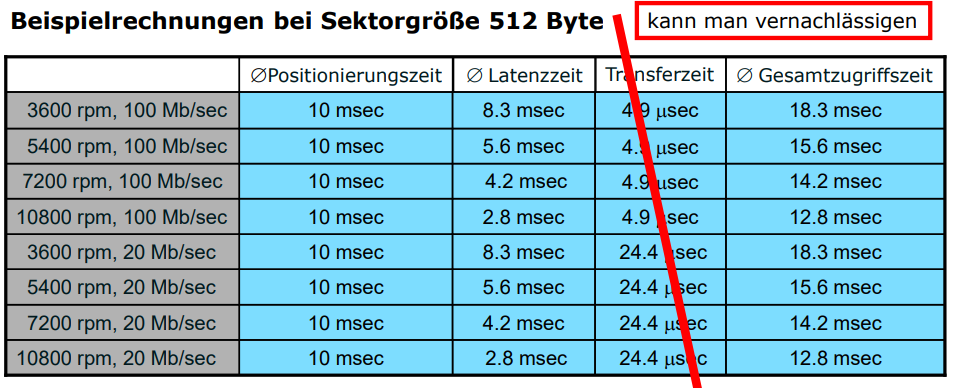
Alternative: Solid State Disk (SSD)
- Hier werden zum speichern Halbleiterbausteine wie beim RAM verwendet
- Es gibt zwei große verfahren:
- Flash-Specher:
- Nicht flüchtig (verliert also seinen zustand nicht, wenn er keinen strom mehr bekommt)
- sehr energieeffizient
- Kurze Zugriffszit ~
- SDRAM
- Flüchtig, deswegen nicht für langzeitspeicher geeignet
- Allerdings als cache für die SSDs
- Ist allerdings auch seeehr schnell
- aber Stromineffizienter
- Flash-Specher:
- Vorteile:
- kein verschleis weil keine mechanischen teile
- Kann besser mit äußerlichen Einwirkungen umgehen
- Ideal für Anwendungen mit niedrigem energieverbrauch
- Nachteil:
- Deutlich Teurer als Festplatten
- Nicht beliebig oft wiederbeschreibbar (flash: 100.000 bis 5 Millionen Schreibyklen)
- Daher benutzen die meissten modernen SSds Reserve-Zellen und Wear-leveling-Algorithmen
Das problem mit dem Hauptspeicher
- Der adressraum von heutigen Computern, ist aufgrund von 64-Bit Prozessoren sehr groß
- Bei busbreite sind beispielsweise Speicherzellen adressierbar
- So viel speicher hat aber niemand, weils einfach unendlich teuer wird
Daher: Festplatte als virtuellen Arbeitsspeicher verwenden
- Der nutzer kriegt davon eig nix mit
-
Wie sieht das dann in der Praxis "unter der haube" aus?
- Multi-User: nicht jeder benutzer kriegt den kompletten hauptspeicher zugeschrieben
- Programme werden nicht für einen spezifischen rechner geschrieben, sondern sehr generalisiert
-
Ausweg?
- Benutze die Festplatte als erweiterten Hauptspeicher
- Hier sollen dann sachen die noch gebraucht werden, aber nicht unbedingt dringend gebraucht werden gelagert werden, sobald nicht mehr genug platz im Hauptspeicher ist
Ja aber was machen wir jetzt mit dem Adressraum?
-> Virtueller adressraum
- Jeder Prozess bekommt einen virtuellen Adressraum
- Diese virtuellen adressräume werden vom Betriebssystem verwaltet
- Das OS hat also eine "übersetzungstabelle", denn wenn z.b. Word denkt, dass es auf memory adresse 0x10331 zugreift, weiss das OS, dass die daten in 0xff781 liegen.
- Zudem verwaltet das Betriebssystem welche programmteile im Ram gehalten werden
- und wann welche daten in den festplatten-ram (SWAP) ausgelagert werden
- In diesem zusammenhang werden konzepte wie
- Paging
- Segmentierung
- angewandt
Segmentierung
- Unterteilung des Virtuellen Speichers in Segmente unterschiedlicher Größen
- Wenn ein programm versucht ausserhalb seiner Segmentgrenzen zu schreiben gibts den bekannten segmentation fault
- und wenn nen angefordertes segment erst garnicht existiert, gibts den auch
- Das betriebssyteme ist dafür verantwortlich, welche segmente im ram liegen und welche weggeworfen werden können und welche weggeworfen werden
Paging
Grundidee
- Der Virtuelle Speicher wird auf dem Sekundärspeicher abgelegt
- dabei wird er in seiten fester größe unterteilt
- der hauptspeicher besteht aus page-frames, die jeweils eine Seite aufnehmen können
- Eine Seitentabelle (page table) gibt an, welche seitenrahmen durch welche Seiten belget sind
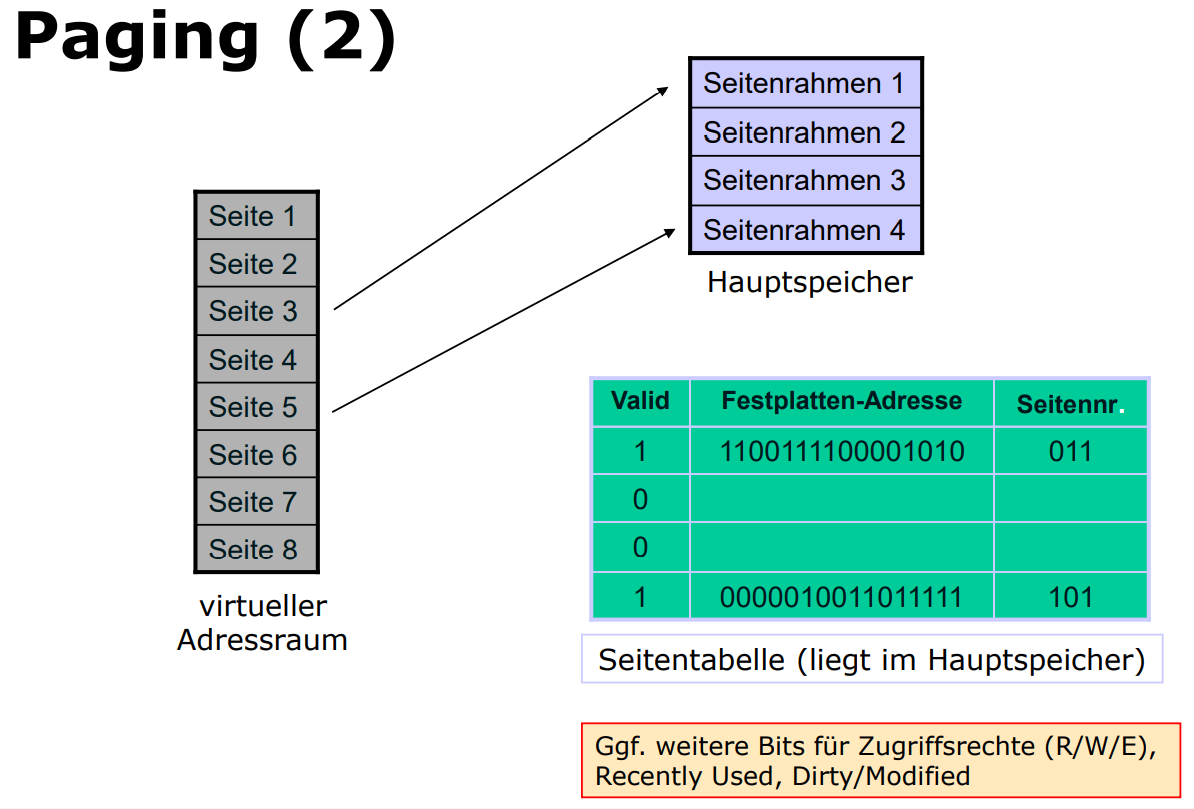
Paging: Zugriff auf Datenseite
- Überprüfe ob Datenseite im Hauptspeicher liegt;
- If Seitenfehler (page fault)
- then Überprüfe ob ein Seitenrahmen im Hauptspeicher leer ist;
- if Kein seitenrahmen leer
- then Verdränge eine Seite ausm hauptspeicher und aktualisiere dann die seitentabelle
- Schreibe Die datenseite in den Freien Rahmen und aktualisier die tabelle
- auf im Hauptspeicher zugreifen
- Wir verweisen wieder auf die Verdrängungsstrategien
Übersetzung von virtuellem Speicher auf physikalischen Speicher
- macht eine MMU (memory Management Unit)
- Ist heutezutage direkt im Prozessor (früher North-Bridge)
- Cache für zuletzt benutzte Pages
(Translation Loojkaside Buffer, TLB) - Falls nicht in TLB aus (mehrstufiger) Seitentabelle Berechnen
- das erfordert bis zu 5 Hauptspeicherzugriffe und ggf. Pagefaults (+ handling) falls die seitentabelle nicht vollständig im speicher ist
- Caches:
- PIPT (Physicalle Indexed, Physically Tagged)
- Einfach aber langsam wegen MMU-Aufrufen
- VIVT (virtually Indexed, Virtually Tagged)
- sehr schnell, aber Homonyme/Synonyme
- VIPT (Virtually Indexed, Physically Tagged)
- für schmale indices: Index der Virtuellen adresse stimmt mit phys. Adresse überein
- in Frage kommendes Cache-Set kann parallel zum MMU Aufruf geladen werden
- PIPT (Physicalle Indexed, Physically Tagged)
Speed-up vs. Security
Meltdown
- CPU- Branch-Prediction Exploits
-
Idee:
- Greife auf Kernel-Speicher zu (ohne berechtigung)
- Das wirft logischerweise ne Exception
- Während die Exception behandelt wird, wird allerdings auf den daten die bereits geholt wurden aufgrund der Branch-prediciton spekulativ weitergerechnet
- Hat messbare effekte auf den Cache, die nicht zurückgesetzt werden
-
Auslesen der Informationen
- Je nach Speicherinhalt wird eine andere Seite in den Cache geladen
- anderer Prozess überprüft dann anhand von Zugriffszeiten welche Seite geladen wurde
- Dadurch kann man rückschlüsse auf den Speicherinhalt erziehlen
- Auslesegeschwindigkeit ~500 kB/s
-
Wat kann man dagegen machen?
- Auf der OS-Ebene schon den speicher besser isolieren und keinen zugang zum Kernel zulassen
- Mikrocode Updaten
Spectre V1
- schläust sich in laufende Prozesse ein
- kann dann auf den jeweiligen User-Space zugreifen
Spectre V2
- Branch prediciton manipulativ trainieren (Context A)
- Spekulative Code-execution ausnutzen, wie oben schon benannt (Context B)
- denn oft wird nur ein teil der virtuellen speicheradresse für den Sprungcode verwendet
- Und alle prozesse eines Kerns nutzen die selbe branch perediction engine
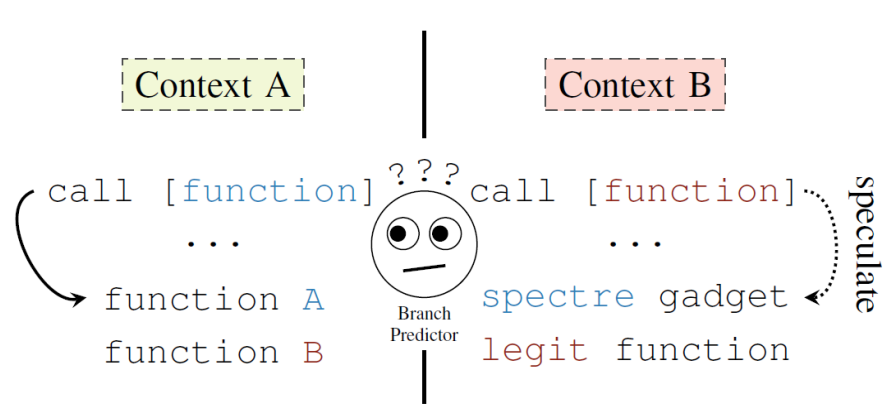
- Gegenmaßnahmen:
- SpectreV1:
- Bounds check Bypass
- absichtlich ungenaue zeitmessungen
- Spectre V2
- Branch Target Injection
- Maßnamen auf OS-Ebene
- Microcode-Updates
- weitere sicherheitsmechanismen
- allerdings auch hier wieder merkbare Leistungseinbußen
- Branch Target Injection
- Bounds check Bypass
- SpectreV1:
Parallelverarbeitung
Formen der Parallelität
-
Bis etwa 1985 haben wir das auf bitebene gemacht, also hatten wir kombinatorische addierer und Multiplizierer die immer alles 1zu1 verglichen haben, das wurde dann irgendwann unpraktisch, weil wir ja immer größere wörter in memory haben, was zu mehr und mehr pain geführt hat
-
Heutezutage machen wir das Auf instruktionsebene, also werden immer mehrere instruktionen gleichzeitig ausgeführt, anstelle von einigen operationen die "gleichzeitig" im ram gespeichert und immer sequenziell aisgeführt werden
- Das kann allerdings ab > 4 Cores problematisch werden - was zu hindernissen bei effizienz und optimierungen führt
-
Als alternative dazu gibt es auch die paralelität auf Prozessorebene
- nur damit sind beschläunigungen um den Faktor 50 und mehr möglich (allerdings is Amdahl's Law zu beachten)
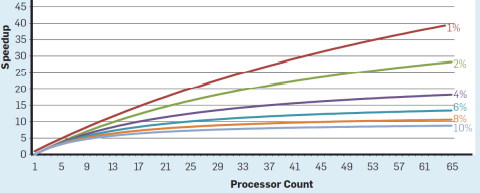
Amdahl's Law
-
= Relative Größe des Programmanteils, welcher leider nicht massiv hip und multithreaded werden kann
-
= Anzahl der massiv coolen Kerne
-
Ideal wäre natürlich, wenn wir dat alles gleichmäßig aufteilen könnten (logischerweise) geht nur leider iwie nicht ganz so gut auf
-
Beschleunigung:
-
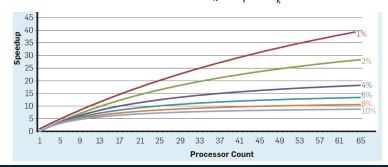
Formen der Parallelverarbeitung auf prozessor-/ Rechnerebene(1)
Arrayprozessoren
- Viele Prozessoren die gleich sind und eventuell lokalen speicher haben
- Jeder dieser prozessoren hat seine eigene Steuereinheit
- Und alle haben immer dieselbbe Instruktionsfolge
- Bsps:
- Illiac IV
- CM-2
Wie machen wir dat sinnvoller? -> Wir machen die einzelnen Prozessoren in der Datenvararbeitung unabhängiger machen
Multiprozessoren:
- bestehend aus mehreren (seperaten) Prozessoren und haben insgesamt einen (realtiv großen) hauptspeicher
- die kommunizieren über den gemeinsamen speicher
- Allerdings kann das zu performanceprobleben füren wenn viele prozessoren gleichzeitig auf den speicher zugreifen wollen
Multi-Core Prozessoren
- Mehrere prozessoren auf einem chip die evtl gemeinsamen Cache und ggf. direkte Kommunikationsmöglichkeiten untereinander haben.
Koprozessoren
- Sollen hauptsächlich den hauptprozessor entlasten
- sind daher meisstens auf eine bestimte menge an spezialisierten Aufgaben Spezialisiert
- Wie z.b. GPUs für alles das wofür man ne Grafikkarte braucht
- Die dinger haben scheinbar ne große Ähnlichkeit zu Vektorprozessoren
- Und dann gibts natürlich noch die absoluten chads: die mathemathischen Koprozessoren die unanfälliger für die nervigen Floating-Point issues sind.
Multicomputer
Man kanns natürlich maximal übertreiben und mehrere computer zusammenstrappen.
- Dabei haben sie kein shared memory
- Die prozessoren kommunizieren über kommunikationstunnel mit gewissen protokollen (nachrichten)
- Dadurch wird das potentiell sehr komplex, dafür aber "beliebig" expandierbar
Beispiele für parallele Rechnerarchitekturen:
- Symmetrische multiprozessoren (SMP)
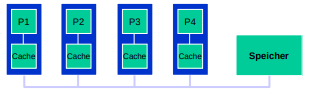
- Dat is leider oft busbasiert und nutzt einen gemeinsamen Speicher
- Das sind halt homogene Prozessoren
- Dabei wird durch lokale Caches die Speicherlatenz verringert
- leider können dabei diskrepanzen zwischen dem Cache und dem gemeinsamen Speicher entstehen, die zu komplikationen führen
- Damit das passiert, müssen alle caches permanent "überwacht" werden, damit alle diskrepanzen frühzeitig behoben werden können
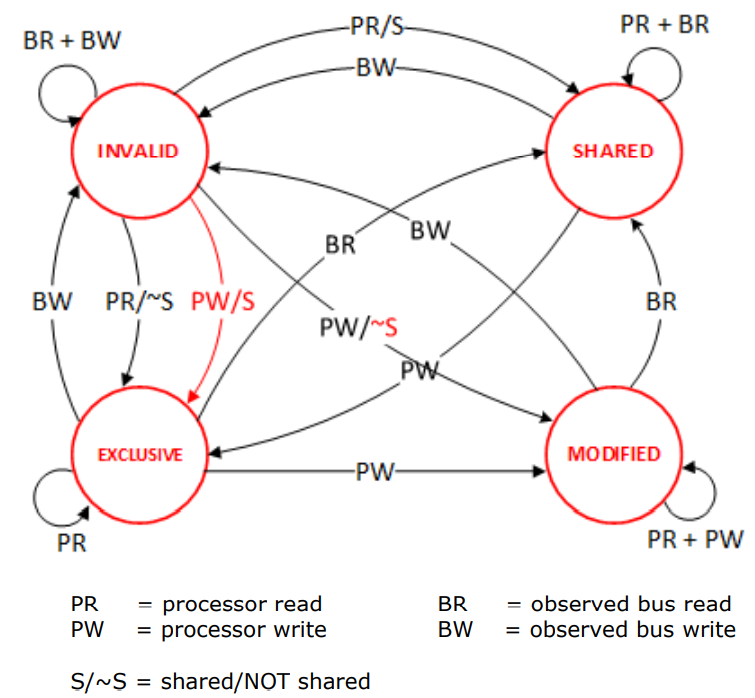
Cache Koeärenz
- z.B. MESI-Protokoll
- Modified:
- Einzige, veränderte kopie
- Exklusive:
- Einzige unveränderte Kopie
- Shared:
- mehrere unveränderte kopien
- Invalid:
- ungültige kopien
- Modified:
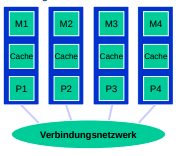
- Systeme mit Verbindungsnetzwerg und dezentralisiertem gemeinsamen Speicher:
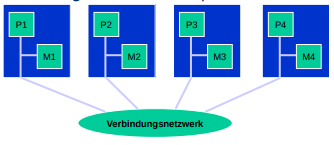
-
Mit dieser Technik können sehr riesige Speichermodule realisiert werden.
-
System mit Dezentralisiertem Speicher mit Verbindungsnetzwerk und zusätzlichem lokalen cache
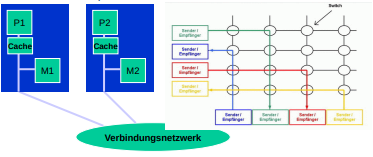
- Dann gibt es noch die Parallelen Rechnerarchitekturen die ein Verbindungsnetz und viele "kleinere" lokale speicher verwenden.
- Hier ist der Prozessoroverhead hoch, weil jedes system eigenständig ist und immer alles an die jeweils anderen weitergeben muss.
- Dabei ist der direkte Zugriff auf den lokalen speicher einer anderen maschine nicht möglich. Man muss alles anfragen
- Dadurch, dass mehr anfragen / antworten gebraucht werden um dasselbe zu erreichen wie bei den "simpleren" systemen wird die "normale" usage komplizierter.
- dafür ist dieses System allerdings pysikalisch skalierbarer, da jede einheit alleine agiert und durch das Verbindungsnetz die Aufgaben aufgeteilt werden können
Verbindungsstrukturen
-
Wie schnell die maschinen untereinander kommunizieren können ist ausschlaggebend für die allgemeine Performance, da durch übermäßiges Warten prozessorzeit verloren gehen könnte
-
Zudem ist zu beachten, dass nicht unbedingt jedes Problem direkt für Parallelisierung geeignet ist, da manche sachen so stark aufeinander aufbauen, dass mehr zeit verschwendet würde, wenn die prozessoren aufeinander warten, als wenn es einer in einem zug "alleine" machen würde
-
Um die Datenverarbeitung zu maximieren muss man zwischen diversen Strukturen wählen, welche alle andere Vorteile im hinsicht zu Kosten und Leistung haben
Modellierung von Verbindungen
-
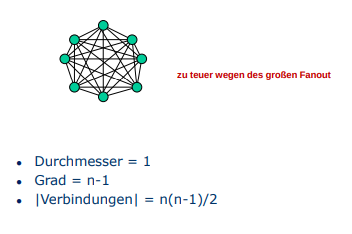
Die Topologie eines Parallelrechners wird durch einen abstrakten Graphen dargestellt mit
-
- Menge der Knoten, diese repräsentieren Prozessoren oder switches
-
- menge der Kanten. Diese Repräsentieren die Verbindungen zwischen den einzelnen Knoten (Switches und CPUs)
-
{Länge des kürzesten Pfades von v nach w}
-
-
Bsp:
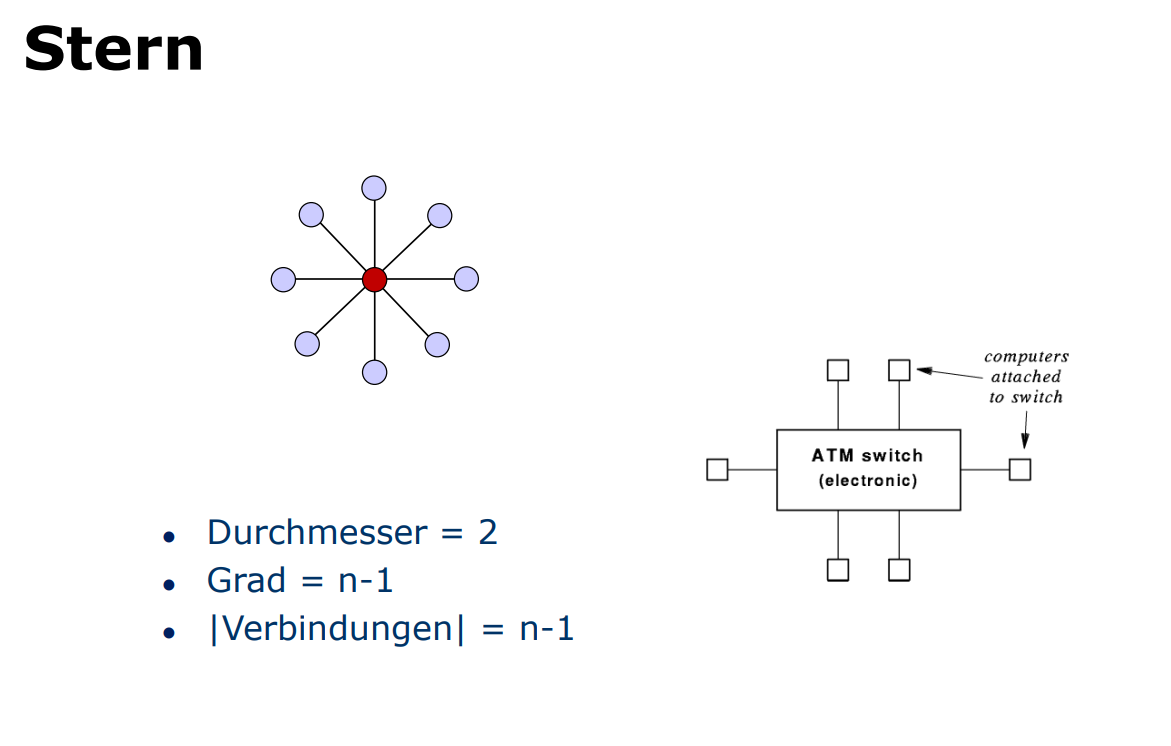
Stern
Andernfalls gibt es noch den stern als Verbindungsmodell, hierbei läuft alle Kommunikation durch einen Knotenpunkt
Ebenso kann mann einen Bus als Stern Modellieren, allerdings ist dann hierbei zu beachten, dass der Mittlere Punkt keine Logik verarbeiten kann. Leider gibt es dabei aber wieder denselben "Flaschenhals" (Bottleneck) wie beim Stern, denn es kann nie schneller Kommuniziert werden als der Mittlere Punkt / Das Switchboard Zulässt
Ring
Dann gibt es noch das Ring-Modell, was man sich wie einen Redekreis vorstellen kann. Hierbei kursiert ein sog. "Ring-Token" was wie der mystische "Gesprächsstein" fungiert, denn ein mitglied des Ringes darf nur dann etwas senden, wenn es diesen Token hat.
- Durchmesser =
- Grad =
- | Verbindungen | =
CDDI / FDDI-Ring
[Copper / Fiber Distributed Data Interconnect]
Characteristika:
- Besteht aus den komischen Sitzkreis-Ringen die oben beschrieben wurden
- Allerdings hat das ding zwei davon, die gegenläufig sind, also in die jeweils andere Richtung voneinander Laufen.
- Dadurch wird die Fehlertoleranz erhöht
MESH ("torusähnliches Gitter")
- wird z.b. bei MPPs verwendet
- Durchmesser =
- Grad =
- | Verbindungen | =
HYPERCUBE (-Dimensionaler Würfel)
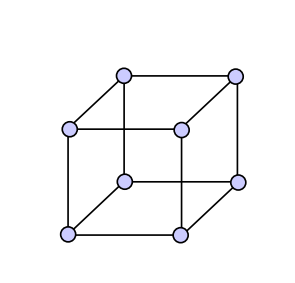
- dieses Modell ist bei einer hohen anzahl von Prozessoren nicht verwendbar, da der grad zu schnell ansteigt.
- Im Bild haben wir z.b. einen 3-Dimensionalen würfel mit 8 ecken, also Knoten. Sprich:
- (Dimension)
- (Nodes)
- Allgemein:
- Durchmesser =
- | Verbindungen | =
Cube Connected Cycle (CCC)
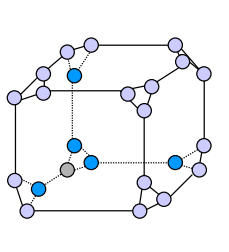
- Prozessoren =
- Durchmesser =
- Grad = 3
- | Verbindungen | =
Beispiele für parallele Rechnerarchitekturen
- Die "heute" gängigen Multi-Core Architekturen
- Dual Core:
- Intel Core 2 Duo
- AMD Athlon X2
- Quad Core:
- AMD Phenom II X4
- Intel Core 2 Quad
- Intel Core i7
- Octa Cores (Und darüber hinaus):
- AMD Ryzen 9 (bis zu 16 Kerne + 32 Threads)
- Intel Core i9 (bis zu 18 Kernen + 36 Threads)
- Dual Core:
Beispiel AMD Phenom II X4 (2009)
- Dat teil hat:
- 4 Identische Kerne
- Cache:
- L1: 64 KB / Kern
- L2: 512KB / Kern
- L3: 6144KB Insgesamt
- 45 nm
- 2,8 - 3 GHz
Beispiel: Cell Chip
- Cell Chip
- (IBM, Sony, Toshiba)
- 234 Millionen Transistoren
- 256 Gigaflops (Single prec.)
- CPU: 1 x 64-Bit-Power-PC
- 8 x SPE (Synergistic Processing Element)
Grafikprozessor
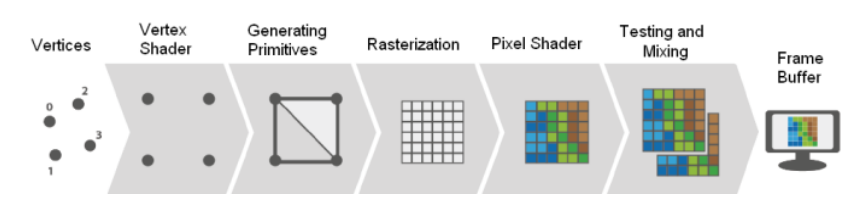
- die Grafikpipeline beschreibt die Schritte in denen eine 3D.Szene auf dem Bildschirm gerendert wird.
- Ein Grafikprozessor setzt diese Pipeline direkt in Hardware um
Aber wie funktioniert das eigentlich?
- Bildpunkte werden durch Vektoren dargestellt
- Eine GPU ist dafür ausgelegt, sehr viele Bildpunkt-Operationen gleichzeitig auszuführen
- Ebenso ist die GPU auf alles ausgelegt, was in der Grafikverabreitung vorkommt wie z.b.Skalarprodukt, Logarithmen etc. Hardwareseitig optimiert
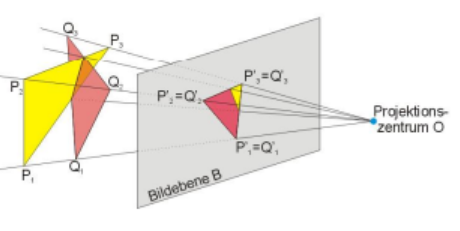
Die Schritte in der Grafikpipeline:
-
Projektion von 3D Auf 2D
-
Beispiel: Zentralprojektion für einen Punkt und das Projektionszentrum ergibt sich die Projektion durch:
-
-
-
Die Operation wird sehr häufig verwendet, daher wird sie durch einen Multiplikationsakkumulator (MAC) direkt in Hardware realisiert
-
-
Matrix
-
Wir betrachten, mal wieder, eine extremst veraltete Grafikkarte als Beispiel:
AMD Radeon RX 580
- GPU "Polars20"
- spezielle Funktionseinheiten:
- 2304 Shading Units (Stream-Prozessoren)
- 36 Compute Units
- 144 Textureinheiten
- 1,257 GHz
- 6200 Gflops
- 2 x 1024KB L2-Cache
Klassifikationsmerkmale bei Parallelen Rechnerarchitekturen
Speichermodell:
- Nicht verteilter Speicher, gemeinsamer Adressraum
- verteilter Speicher, gemeinsamer Adressraum
- verteilter Speicher, getrennte Adressräume
Homogenität der Prozessoren
- homogene Parallelrechner: alle prozessoren sind gleich
- heterogene Parallelrechner: Prozessoren dürfen sich hardwaremäßig unterscheiden
Hirachie zwischen den Prozessoren
- symmetrische Parallelrechner: Die Prozessoren sind bzgl ihrer Rolle im gesamtsystem untereinander Austauschbar.
- nichtsymmetrische Parallelrechner: es gibt masters und Slaves
Eigenständigkeit der Prozesoren:
- lose gekoppelter Parallelrechner: Netzwerk von eigenständigen Rechnern
- eng gekoppete Parakkekrechner: physikalisch ein Rechner
Klassifikation nach Flynn [1966]
- SISD (Single Instruction stream, Single Data stream)
- Eine Instruktion betrachtet immer ein Datenteil isoliert und alleine
- So lernen wir Programmierne zu Beginn
- SIMD (Single Instruction stream, Multiple Data streams)
- Eine Instruktion behandelt direkt mehrere Datenteile
- Dieses Modell findet sich in modernen GPUs wieder
- Beispielsweise loopen wir über eine Liste von elementen und rechnen alle + 1
- MISD (Multpiple Instruction stream, Single Data Stream)
- Wenn mehrere Instruktionen verwendet werden um ein Datenteil zu editieren.
- z.b. wenn wir 3 verschiedene Rechenoperationen hintereinander auf ein element ausführen
- MIMD (Multiple Instruction streams, Multiple Data streams)
- Basically "true" multitasking. Mehrere unabhängige Systeme interagieren mit mehreren unabhängigen Datensätzen
Codierung (Von Zeichen)
Motivation?
- Ein Rechner kann traditionell leider keine
- Zeichen verarbeoten
- mit zahlen rechnen
- Bilder / Grafik darstellen
- Wir können zwar theoretisch algorithmen bauen, die diese sachen implementieren, allerdings müssen wir diese algorithmen in ein vom Computer verstandenes Binärformat umwandeln (Kompillieren)
ASCII
Wir reden erstmal über Primitive Dinge: also T-Scr.. ich meine Ascii (American Standard Code for Information Interchange)
-
Mit Ascii kann man (sehr begrenzte) Zeichen darstellen und deswegen hat man angefangen Alternativen zu bauen
-
Man kann mit Ascii zudem nur lateinische Buchstaben darstellen, und auch nur die, die im englischen sehr aktiv genutz werden, da man aufgrund von bandbreitenlimitierung ein (weirdes) 7-Bit format gewählt hat.
-
Dann hatten wir eine radikal bessere idee als Ascii: Unicode
Unicode
-
Auch bekannt als UTF-8
-
8 weil ein zeichen bis zu 8 bit lang sein kann.
-
Zudem hat Unicode auch support für Ascii, indem man nur den ersten byte der sequenzfolge nutzt. Da ascii praktischerweise in einen byte passt, ist damit das gesamte Ascii spektrum auch abgebildet
-
Wenn ein Zeichen nicht Ascii codiert ist, dann ist es zwischen 2 und 4 Byte lang
Definition: Code
Das werdet ihr in Info3 wieder sehen :P
- Sei ein endliches Alphabet der größe
- Die Menge oder heißt Code falls injektiiv ist.
- Die menge
- Ein Code heißt Code fester Länge
- Beobachtung: Für einen Code fester Länge gilt .
Probleme bei Binär-encoding:
- Daten können in der Transmission beschädigt werden, weswegen dann Interpätationsschwierigkeiten aufkommen
Was kann alles Passieren?
-
Bitstellen können Geflipped werden (Der mysteriöse Bitflip)
-
Die distanz zwischen zwei bitfolgen könnte sich verändern, dass dazwischen mehr 0en stehen als geplant.
-
Ein Übertragungsfehler heisst einfach, wenn gilt.
-
Hier ein beispiel wie die funktion funktioniert:
-
Wat bei der krassen Fehlerhaft übertragung helfen könnte wäre eine FEHLERERKENNUNG (BOAH KRASS)
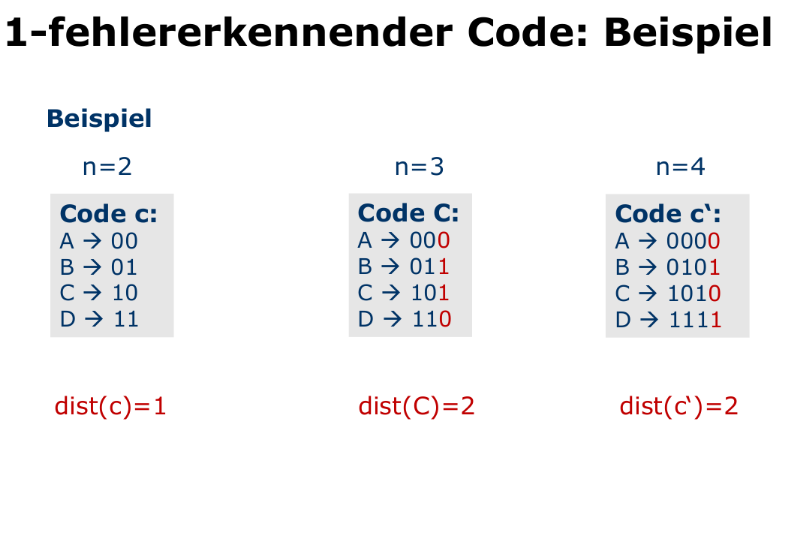
Fehlererkennender Code
Sei ein code fester Länge von
- Der kürzeste Abstand
- zwischen zwei Codewörtern wird Distanz des Codes genannt. Der code heisst -fehlererkenned, wenn mder Empfänger in jedem fall entscheiden kann, ob ein gesendetes Codewort durch flippen von Bits verfälscht wurde.
Lemma
Ein Code von fester Länge ist genau dann -fehlererkennend, wenn gilt.
-
Wir erkennen Fehlerhaften code indem wir parity-checks (Paritätstests) durchführen, und prüfen, ob sich die beiden bitfolgen an einer oder mehreren Stellen unterscheiden
-
Man kann z.b. einen Parity-Bit (Paritätsbit) an eine bitsequenz hängen um mit dem abschliesenden bit überprüfen zu können, ob die datenübertragung erfolgreich war.
Beweis Lemma [Fehlerkorrektur]
Idee
- Sei . Da -Fehlererkennend ist, muss gelten.
- Wir haben zwei Codewörter , die sich an genau Stellen unterscheiden. Die Bitfolge die man erhält, wenn dieser stellen in geflippt werden, underscheidet sich in Bit von
- Ist dann und es kann nicht mehr eindeutig bestimmt werden, zu welchem Codewort korrigiert werden muss
- Ist , unterscheidet sich von an mehr als Stellen. Gleiches gilt dann auch für alle anderen Codewörter und bitfolgen die sich von an höchstens stellen unterscheiden. Also ist eine eindeutige Korrektur zu c(a_j) möglich
1-Fehlerkorrigierender Code
Um 1 Fehler Korrigieren zu können benötigt man mindestens
Hamming code
Idee:
- Wir könnten normale Bitsequenzen um Prüfbits erweitern
- Die Prüfbits müssten dann so belegt werden, dass jedes Codewort verschiedene Parity-checks bestehen kann
- Genau die bitstellen (also 1, 2, 4, 8,...) sind Prüfbits
- Das prüfbit an der Stelle muss so gewählt werden, dass alle Bitdarstellungen die an der -ten Stelle eine 1 haben, den Parity-check bestehen
Hamming Code an einem Beispiel
-
Uncodiertes Zeichen:
-
-
Wie sieht nun der Hamming-Code dieses Zeichen aus?
-
Der Code wird auf 21 Bitstellen verlängert
-
Die zweierpotenz-Bitstellen werden als Überprüfungsbits benutzt 0 1110 _ 101 0000 _ 111 _ 1 _ _
wobei Bitstelle die Bitstellen Überprüft deren Binärdarstellungen an der -Ten Stelle eine 1 haben. Die belegung der Bitstelle 2^j ergibt sich jeweils aus der Summe der (belegungen der) überprüften Bistellen modulo 2
Hamming Code Berechnen
- Wie viele bits brauchen wir für die Parity?
- Um einen Hamming code zu berechnen schauen wir uns die datenlänge von dem ding, was wir senden wollen an.
- die menge an Paritätsstellen ist immer der wo (aufgerundet)
- Das macht bei 11-bit also
- Stellen bestimmen
- Jetzt schauen wir uns die bit-nachricht an, und stellen an die indizes die mit dem Wert einer zweierpotenz übereinstimmen eine Leere stelle, die wir mit der Parity-Zahl füllen werden.
- Bei unserer 11-Bit langen Datei sind das die Indizes 1, 2, 4 und 8.
- Parity Berechnen
- Jetzt kommen wir an den lustigen Teil des ganzen
- Wir schauen uns die binärrepresenationen der Indizes der 1en und 0en an.
- Sprich, wenn wir eine Zahl mit 15 Stellen haben (wie bei unserer ursprünglich 11-bit Langen Datei) ist das 1111, 1110, 1101 etc. you get the point.
- Wir schauen uns dann alle Zahlen an, deren Index eine 1 ganz am ende hat.
- Hier bemerken wir, dass eine unserer Parity Zahlen auch eine 1 am ende hat, nämlich die 1 (oHhHHHHh).
- Das ist absichtlich, denn wir werden diese Zahl nutzen um die Menge an 1en an den stellen die wir gerade betrachten gerade zu machen.
- wenn wir also an index 7 und 3 eine 1 stehen haben, und sonst nirgendwo schreiben wir bei index 1 eine 0 hin, da wir ja schon 2 1en haben und 2 ist gerade.
- ebenso, würden wir wenn wir bei index 9, 7 und 3 1en hätten eine 1 an den index 1 schreiben, damit wir am ende 4 1en in der Gruppe hätten. (Damit unsere Zahl wieder gerade wäre)
- Das wiederholen wir jetzt mit allen zahlen die an der 2. stelle des Index eine 1 haben usw.
- Am Ende sollten dann alle lücken gefüllt sein.
Bussysteme
Memory - I/O Busse
- Wat das eig?
- ein Elektronisches leitungsbündel in einem digitalen Rechner
- Kommunikationsmedium auf dem daten fließen können
- Zwischen CPU und Hauptspeicher
- zwischen CPU und I/O Geräten
- zwischen Hauptspeicher und I/O-Geräten
- normierte Stecker
- standarisierte Interpretation der einzelnen Leitungen
Heutige Bussysteme
- USB
- SATA
- Thunderbolt
- AGP
- PCI-E
Morgige?
- Thunderbolt?
- USB 4?
Selbstaktende Codierung
-
Problem:
- Nur eine Leitung bei srielle Übertragung
- fehlende Synchronisierung / kein seperates Takt signal
- Wann beginnen einzelne bits? -> Es muss ein takt aus dem datensignal ausgelesen werden können
- Keine Steuersignalleitungen
- Wo sind die blockgrenzen? was sind bus befehle bzw. daten?
- Steuersignale sind bestimmte bitfolgen
- Wo sind die blockgrenzen? was sind bus befehle bzw. daten?
-
Manchester Code:
- übertrage 2 Bits pro Datenbit
- Übergang in Taktmitte codiert Informatin
- fallende und steigende Flanke
- andere Übergänge: Takt-Rückgewinnung
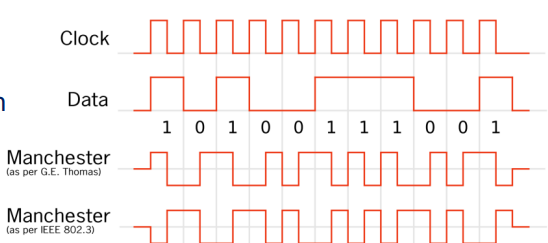
-
-Codes
- Z.b. bei PCI-E, SATA, USB (ab 3.0)
- codiere Datenbits in Übertragungsbit (früher heute: )
- ~4 Möglichkeiten für jede -Bitfolge erlaubt primitive Fehlerkorrektur
- einige -Bitfolgen repräsentieren Steuersignale
- für : Zwölf besondere Bitfolgen
- für : Codiert über die ersten zwei bit ("Präambel")
- "01": Nutzerdaten
- "10": Steuer-/Nutzerdaten
- "00"/"11": Nicht erlaubt, Fehler!
Prinzipieller ablauf einer Kommunkation
Datentransfer vom Hauptspeicher zu einer Festplatte
- Der Prozessor fragt daten an
- Liest die daten vom Ram in den cache
- Fragt an ob er daten schreiben kann
Datentransfer von einer Festplatte zum Hauptspeicher
- Prozessor fragt daten an
- Prozessor sagt der festplatte was er will
- Festplatte schreibt das ind en ram
Direct memory Access
- Da ja leider die datenübertragung über den Prozessor den prozessor unnötig belastet kann ein eigenständiger DMA-Controller eingeführt werden
- Dieser kann dann selbstständig daten aus dem sekundären (langzeit) Speicher in den RAM schieben wenn der CPU sie verlangt
- Dadurch wird der Prozessor weniger Belastet
- und es gibt unterm Strich einen höheren Datendurchsatz
Optionen eines Busses
| Schneller | Billiger |
|---|---|
| Seperate Adress- und Datenleitungen | Multiplexen von Adress- und Datenleitungen |
| Breiter | Schmaler |
| Mehrere Busmaster erlaubt (Erfordert Schiedsrichter) | Nur ein Busmaster |
| synchrone Übertragung | asynchrone Übertragung |
Zu guter letzt: Vielen dank fürs Lesen! Ich hoffe ich konnte ein wenig behilflich sein. VG, Tobi :)